Digital transformation doesn’t stop creating surprise, admiration, innovation … but also deception and divide. In 2023, Gen AI has taken the lead regarding use, high speed engagement, discovery, and implementation.
How Tech Executives Rank Other C-suite Leaders’ Digital Skills and Mindset
They give the highest marks for proficiency and mindset (the ability to imagine digital solutions) to chief marketing, strategy and operations officers and CEOs among non-tech roles – and rank legal and HR leaders lowest, on average. Several potential reasons could explain this « gap »:
one of it probably being the traditionally less developed business partnership among CTO/CIO functions and HR and especially Legal departments as these functions either work with robust legacy or with low or no IT solutions to produce their output;
another root cause of underestimated « mindset » and « proficiency » might be stronger compliance requirements usually existing for HR and Legal functions, requirements natively less open for technical disruption;
finally, both functions are frequently « (dis)qualified » by IT management as being too « open to shadow IT » solutions.
Three-Quarters of CEOs Have Tried ChatGPT Since Its Launch
A third of chief executives who have used the tool for work used it for writing and communication. More than 20% have employed it for general research, followed by market research and presentations (13% each).
Definitely a great start compared to significantly lower C-level adoption of previous IT innovations and disruptions. However, given the extremely broad potential among all other functions within an organization, from front lines to back office and all support functions, it’s critical to involve executives and boards in all inititiatives identified or to be identified as critical and potentially disruptive and/or transformative for the organizations future.
Otherwise, the risk to underestimate value and underallocate investments could be huge (e.g. past experience with social network, IoT, data science … too often considered being « for their kids or for freaks » than for their organizations and business).
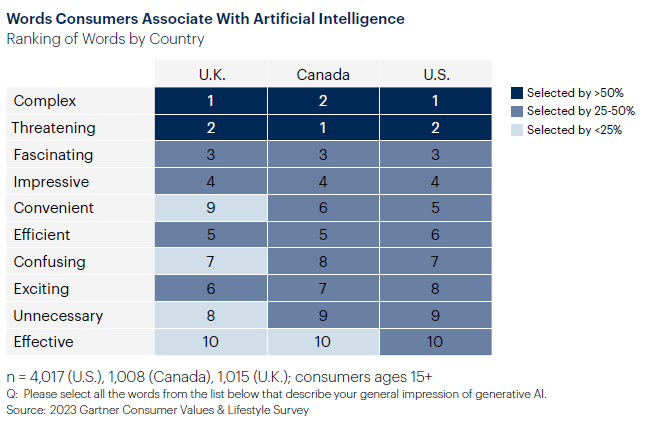
As Executives Laud AI, Consumers in the U.K., Canada and U.S. Express Fear
More than half of consumers in all three countries chose “complex” and “threatening” to describe AI, while “effective” was the least-selected word.
Not really a surprise as Big Tech is considered being a cunsumer unfriendly « oligopoly » after the skyrocketing of their market capitalization since Covid.
Fastly growing data privacy issues and cyber security incidents naturally add concerns regarding this technological disruption mainly built on Big Data and AI usage most consumers didn’t imagine prior to ChatGPT going mainstream.
How to Cope With Global Digital Divides
At least four digital infrastructures are emerging as ideology splits the world — in China, the U.S., the EU, and Russia. After three decades of global consistency for multinational companies, this shift has radical implications for business.
The number of national policies restricting data flows or access more than doubled from 2017 to 2021. With AI regulation following the same path, hoping this divided world will “return to normal” is futile. And a purely tactical C-suite response to one digital policy at a time is too costly.
To reduce risks to growth, executive leaders should instead view geopolitical and digital tensions strategically while reacting to measures in specific jurisdictions. That means:
Adjusting local enterprise technology architectures, operating models and corporate structures as needed
Exiting the market as the final resort if following the steps outlined in Figure 1 does not sufficiently mitigate operational risks
Assess Country Dependency Risk — Including Sovereign Data and Digital Strategies
Executive leaders should first determine the business impact of geopolitical and digital risks in a country — including regulations — and consider appropriate mitigating steps. For example, some multinational enterprises that continued to operate in Russia after February 2022 had to adjust their technology stack when one or more of their technology suppliers left the country.
Many multinational organizations are assessing the potential for a similar problem to arise in other regions of high tension. They also now need to manage China’s Personal Information Protection Law (PIPL) and India’s new Digital Personal Data Protection Act (passed in August 2023 but not yet effective) while remaining compliant with the EU’s general data protection regulation (GDPR).
Because digital technology is central to business, digital regulations affect almost everything a company does (as well as nearly all consumers and public-sector activities). Executive leaders must, therefore, take a broad view of how their enterprise uses data (see Figure 2).
Evaluate your digital risk in a country using Figure 2 as a guide. Take each element as a potential risk area you need to gauge due to one or more sovereign data and digital regulations. While this process will depend on where and how your company operates, a standardized assessment across all elements will help you make consistent, actionable changes faster at a strategic level.
Executive leaders addressing the enterprisewide impact of increasing digital regulations should:
Identify the business scenarios and outcomes that are hardest to govern because of, for example, geographic and organizational diversity, complexity and autonomy.
Consider establishing a virtual team to govern data and analytics throughout business functions and across geographies to address one of these situations. Using this connected governance framework will involve creating a proof of concept to test the benefits, risks and impacts associated with the scenario.
EIOPA’S DIGITAL TRANSFORMATION STRATEGIC PRIORITIES AND OBJECTIVES
EIOPA’s supervisory and regulatory activities are always underpinned by two overarching objectives: promoting consumer protection and financial stability. The digital transformation strategy aims at identifying areas where, in view of these overarching objectives, EIOPA can best commit its resources in view of the challenges posed by digitalisation, while at the same time seeking to identify and remove undue barriers that limit the benefits.
This strategy sits alongside EIOPA’s other forward thinking prioritisation tools –
the union-wide strategic supervisory priorities,
the Strategy on Cyber Underwriting,
the Suptech Strategy
– but its focus is less on the specific actions needed in different areas, and more on how EIOPA will support NCAs and the pensions and insurance sectors in facing digital transformations following a
technologically-neutral,
future-proof,
ethical
and secure approach
to financial innovation and digitalisation.
Five key long-term priorities have been identified, which will guide EIOPA’s contributions on digitalisation topics:
Leveraging on the development of a sound European data ecosystem
Preparing for an increase of Artificial Intelligence while focusing on financial inclusion
Ensuring a forward looking approach to financial stability and resilience
Realising the benefits of the European single market
Enhancing the supervisory capabilities of EIOPA and NCAs.
These five long-term priorities are described in the following sections. Each relates to areas where work is already underway or planned, whether at national or European level, by EIOPA or other European bodies.
The aim is to focus on priority areas where EIOPA can add value so as to enhance synergies and improve overall convergence and efficiency in our response as a supervisory community to the digital transformation.
LEVERAGING ON THE DEVELOPMENT OF A SOUND EUROPEAN DATA ECO-SYSTEM ACCOMPANYING THE DEVELOPMENT OF AN OPEN FINANCE AND OPEN INSURANCE FRAMEWORK Trends in the market show that the exchange of both personal and non-personal data through Application Programming Interfaces (APIs) is a leading factor leading to transformation and integration in the financial sector. By enabling several stakeholders to “plug” to an API to have access to timely and standardised data, insurance undertakings in collaboration with other service providers can timely and adequately assess the needs of consumers and develop innovative and convenient proposals for them. Indeed, there are multiple types of use cases that can be developed as a result of enhanced accessing and sharing of data in insurance.
Examples of potential use cases include pension tracking systems (see further below), public and private comparison websites, or different forms of embedding insurance (including micro insurances) in the channels of other actors (retailers, airlines, car sharing applications, etc.).
Another use case could consist in allowing consumers to conveniently access information about their insurance products from different providers in an integrated platform / application and identify any protection gaps (or overlaps) in coverage that they may have.
In addition to having access to a greater variety of products and services and enabling consumers to make more informed decisions, the transfer of insurance-related data seamlessly from one provider to another in real-time (data portability) could facilitate switching and enhance competition in the market.
Supervisory authorities could also potentially connect into the relevant APIs to access anonymised market data so as to develop more pre-emptive and evidence-based supervision and regulation.
However, it is also important to take into account relevant risks such those linked to data
quality,
breaches
and misuse.
ICT/cyber risks and financial inclusion risks are also relevant, as well as issues related to a level playing field and data reciprocity.
EIOPA considers that, if the risks are handled right, several open insurance use cases can have significant benefits for consumers, for the sector and its supervision and will use the findings of its recent public consultation on this topic to collaborate with the European Commission on the development of the financial data space and/or open finance initiatives respectively foreseen in the Commission’s Data Strategy and Digital Finance Strategy, possibly focusing on specific use cases.
ADVISING ON THE DEVELOPMENT OF PENSIONS DATA TRACKING SYSTEMS IN THE EU European public pension systems are facing the dual challenge of remaining financially sustainable in an aging society and being able to provide Europeans with an adequate income in retirement. Hence, the relevance of supplementary occupational and personal pension systems is increasing. The latter are also seeing a major trend influenced by the low interest environment consisting on the shift from Defined Benefit (DB) plans, which guarantee citizens a certain income after retirement, to Defined Contribution (DC) plans, where retirement income depends on how the accumulated contributions have been invested. As a consequence of these developments, more responsibility and financial risks are placed on individual citizens for planning for their income after retirement.
In this context, Pensions Tracking Systems (PTS) can provide simple and understandable information to the average citizen about his or her pension savings in an aggregated manner, typically conveniently accessible via digital channels. PTS are linked to the concept of Open Finance, since different providers of statutory and private pensions share pension data in a standardised manner so that it can be aggregated so as to provide consumers with relevant information for adopting informed decisions about their retirement planning.
EIOPA considers that it is increasingly important to provide consumers with adequate information to make informed decisions about their retirement planning, as it is reflected in EIOPA’s technical advice to the European Commission on best practices for the development of Pension Tracking Systems. EIOPA remains ready to further assist on this area, as relevant.
TRANSITIONING TOWARDS A SUSTAINABLE ECONOMY WITH THE HELP OF DATA AND TECHNOLOGY Technologies such as
AI,
Blockchain,
or the Internet of Things
can assist European insurance undertakings and pension schemes in the implementation of more sustainable business models and investments.
For example, greater insights provided by new datasets (e.g. satellite images or images taken by drones) combined with more granular AI systems may allow to better assess climate change-related risks and provide advanced insurance coverage. Indeed, as highlighted by the Commission’s strategy on adaptation to climate change, actions aimed to adapt to climate change should be informed by more and better data on climate-related risks and losses accessible to everyone as well as relevant risks assessment tools.
This would allow insurance undertakings to contribute to a wider inclusion by incentivising customers to mitigate risks via policies whose pricing and contractual terms are based on effective measurements, e.g. with the use of telematics-based solutions in home insurance. However, there are also concerns about the impact on the affordability and availability of insurance for certain consumers (e.g. consumers living in areas highly exposed to flooding) as well as regarding the environmental impact of some technologies, notably concerning the energy consumption of certain data centres and crypto-assets.
Promoting a sustainable economy is a core priority for EIOPA. For this purpose, EIOPA will specifically develop a Sustainable Finance Action Plan highlighting, among other things, the importance of improving the accessibility and availability of data and models on climate-related risks and insured losses and the role that EIOPA can play therein, as highlighted by the Commission’s strategy on adaptation to climate change and in line with the Green deal data space foreseen in the Commission’s Data Strategy.
PREPARING FOR AN INCREASE OF ARTIFICIAL INTELLIGENCE WHILE FOCUSING ON FINANCIAL INCLUSION TOWARDS AN ETHICAL AND TRUSWORTHY ARTIFICIAL INTELLIGENCE IN THE EUROPEAN INSURANCE SECTOR The take-up of AI in all the areas of the insurance value chain raises specific opportunities and challenges; the variety of use cases is fast moving, while the technical, ethical and supervisory issues thrown up in ensuring appropriate governance, oversight, and transparency are wide ranging. Indeed, while the benefits of AI in terms of prediction accuracy, cost efficiency and automation are very relevant, the challenges raised by
the limited explainability of some AI systems
and the potential impact on some AI use cases on the fair treatment of consumers and the financial inclusion of vulnerable consumers and protected classes
is also significant.
A coordinated and coherent approach across markets, insurance undertakings and intermediaries, and between supervisors is therefore of particular importance, also given the potential costs of addressing divergences in the future. EIOPA acknowledges that AI can play a pivotal role in the digital transformation of the insurance and pension markets in the years to come and therefore the importance of establishing adequate governance frameworks to ensure ethical and trustworthy AI systems. EIOPA will seek to leverage the AI governance principles recently developed by its consultative expert group on digital ethics, to develop further sectorial work on specific AI use cases in insurance.
PROMOTING FINANCIAL INCLUSION IN THE DIGITAL AGE On the one hand, new technologies and business models could be used to improve the financial inclusion of European citizens. For example, young drivers using telematics devices installed in their cars or diabetes patients using health wearable devices reportedly have access to more affordable insurance products. In addition to the incentives arising from advanced risk-based pricing, insurance undertakings could provide consumers loss prevention / risk mitigation services (e.g. suggestions to drive safely or to adopt healthier lifestyles) to help them understand and mitigate their risk exposure.
From a different perspective, digital communication channels, new identity solutions and onboarding options could also facilitate access to insurance to certain customer segments. On the other hand, certain categories of consumers or consumers not willing to share personal data could encounter difficulties in accessing affordable insurance as a result of more granular risk assessments. This would be for instance the case of consumers having difficulties to access affordable flood insurance as a result detailed risk-based pricing enabled by satellite imagery processed by AI systems. In addition,
other groups of potentially vulnerable consumers deserve special attention due to their personal characteristics (e.g. elderly people or in poverty),
life-time events (e.g. car accident),
health conditions (e.g. undergoing therapy)
or people with difficulties to access digital services.
Furthermore, the trend towards increasingly data-driven business models can be compromised if adequate governance measures are not put in place to deal with biases in datasets used in order to avoid discriminatory outcomes.
EIOPA will assess the topic of financial inclusion from a broader perspective i.e. not only from a digitalisation angle, seeking to promote the fair and ethical treatment of consumers, in particular in front-desk applications and in insurance lines of businesses that are particularly important due to their social impact.
EIOPA will routinely assess its consumer protection supervisory and policy work in view of impacts on financial inclusion, and ensuring its work on digitalisation takes into account accessibility or inclusion impacts.
ENSURING A FORWARD LOOKING APPROACH TO FINANCIAL STABILITY AND RESILIENCE ENSURING A RESILIENT AND SECURE DIGITALISATION Similar to other sectors of the economy, incumbent undertakings as well as InsurTech start-ups increasingly rely on information and communication technology (ICT) systems in the provision of insurance and pensions services. Among other benefits, the increasing adoption of innovative ICT allow undertakings to implement more efficient processes and reduce operational costs, enable data tracking and data backups in case of incidents, as well as greater accessibility and collaboration within the organisation (e.g. via cloud computing systems).
However, undertakings’ operations are also increasingly vulnerable to ICT security incidents, including cyberattacks. Furthermore, the complexity of some ICT or a different governance applied to new technologies (e.g. cloud computing) is increasing as well as the frequency of ICT related incidents (e.g. cyber incidents), which can have a considerable impact on undertakings’ operational functioning. Moreover, relevance of larger ICT service providers could also lead to concentration and contagion risks. Supervisory authorities need to take into account these developments and adapt their supervisory skills and competences accordingly.
Early on, EIOPA identified cyber security and ICT resilience as a key policy priority and in the years to come will focus on the implementation of those priorities, including the recently adopted cloud computing and ICT guidelines, and on the upcoming implementation of the Digital Operational Resilience Act (DORA).
ASSESSING THE PRUDENTIAL FRAMEWORK IN THE LIGHT OF DIGITALISATION The Solvency II Directive sets out requirements applicable to insurance and reinsurance undertakings in the EU with the aim to ensure their financial soundness and provide adequate protection to policyholders and beneficiaries. The Solvency II Directive follows a proportional, risk-based and technology-neutral approach and therefore it remains fully relevant in the context of digitalisation. Under this approach, all undertakings, including start-ups that wish to obtain a licence to benefit from Solvency II’s pass-porting rights to access the Internal Market via digital (and non-digital) distribution channels need to meet the requirements foreseen in the Directive, including minimal capital.
A prudential evaluation respective digital transformation processes should consider that insurance undertakings are incurring in high IT-related costs, to be appropriately reflected in their balance sheet. Furthermore, Solvency II requirement on outsourcing and the system of governance requirements are also relevant, in light of the increasing collaboration with third-party service providers (including BigTechs) and the use of new technologies such as AI. Investments on novel assets such as crypto-assets as well as the trend towards the “platformisation” of the economy are also relevant from a prudential perspective and the type of activities developed by insurance undertakings.
EIOPA considers that it is important to assess the prudential framework in light of the digital transformation that is taking place in the sector, seeking to ensure its financial soundness, promote greater supervisory convergence and also assess whether digital activities and related risks are adequately captured and if there are any undue regulatory barriers to digitalisation in this area.
REALISING THE BENEFITS OF THE EUROPEAN SINGLE MARKET SUPPORTING THE DIGITAL SINGLE MARKET FOR INSURANCE AND PENSION PRODUCTS Digital distribution can readily cross borders and reduce linguistic and other barriers; economies of scale linked to offering products to a wider market, increased competition, and greater variety of products and services for consumers are some of the benefits arising from the European Internal Market.
However, the scaling up the scope and speed of distribution of products and services across the Internal Market is an area where there is still a major untapped potential. Indeed, while legislative initiatives such as the
Insurance Distribution Directive (IDD),
Solvency II Directive,
Packaged Retail and Insurance-based Investment Products (PRIIPs) Regulation,
or the Directive on the activities and supervision of institutions for occupational retirement provision (IORP II)16
have made considerable progress towards the convergence of national regimes in Europe, considerable supervisory and regulatory divergences still persist amongst EU Member States.
For example, the IDD is a minimum harmonisation Directive. Existing regulation does not always allows for a fully digital approach. For instance, the need to use non-digital signatures or paper-based requirements as established by Article 23 (1) (a) IDD and Article 14 (2) (a) PRIIPs Regulation can limit end-to-end digital workflows. It is critical that the opportunities – and risks, for instance in relation to financial inclusion and accessibility – that come with digital transformations are fully integrated into future policy work. In this context, the so-called 28th regime used in Regulation on a pan-European Personal Pension Product (PEPP)17, which does not replace or harmonise national systems but coexists with them, is an approach that could eventually be explored taking into account the lessons learned.
EIOPA supports the development of the Internal Market in times of transformation, through the recalibration where needed of the IDD, Solvency II, PRIIPS and IORP II from a digital single market perspective. EIOPA will also explore what a digital single market for insurance might look like from a regulatory and supervisory perspective. Furthermore, EIOPA will integrate a digital ‘sense check’ into all of its policy work, where relevant.
SUPPORTING INNOVATION FACILITATORS IN EUROPE In recent years many NCAsin the EU have adopted initiatives to facilitate financial innovation. These initiatives include the establishment of innovation facilitators such as ‘innovation hubs’ and ‘regulatory sandboxes’ to exchange views and experience concerning Fintech-related regulatory issues and enable the testing and development of innovative solutions in a controlled environment and to learn more as to supervisory expectations. These initiatives also allow supervisory authorities to gather a better understanding of the new technologies and business models taking place in the market.
At European level, the European Forum for Innovation Facilitators (EFIF), created in 2019, has become an important forum where European supervisors share experiences from their national innovation facilitators and discuss with stakeholders topics such as Artificial Intelligence, Platformisation, RegTech or crypto-assets. The EFIF will soon be complemented with the Commission’s Digital Finance platform; a new digital interface where stakeholders of the digital finance ecosystem will be able to interact.
Innovation facilitators can play a key role in the implementation and adoption of innovative technologies and business models in Europe and EIOPA will continue to support them through its work in the EFIF and the upcoming Digital Finance Platform. EIOPA will work to further facilitate cross-border / cross-sector cooperation and information exchanges on emergent business models.
ADDRESSING THE OPPORTUNITIES AND CHALLENGES OF FRAGMENTED VALUE CHAINS AND THE PLATFORM ECONOMY New actors including InsurTech start-ups and BigTech companies are entering the insurance market, both as competitors as well as cooperation partners of incumbent insurance undertakings.
Concerning the latter, incumbent undertakings reportedly increasingly revert to third-party service providers to gain quick and efficient access to new technologies and business models. For example, based on in EIOPA’s Big Data Analytics thematic review, while the majority of the participating insurance undertakings using BDA solutions in the area of claims management developed these tools in-house, two thirds of the undertakings reverted to outsourcing arrangements in order to implement AI-powered chatbots.
This trend is reinforced by the platformisation of the economy, which in the insurance sector goes beyond traditional comparison websites and is reflected in the development of complex ecosystems integrating different stakeholders. They often share data via Application Programming Interfaces (APIs) and cooperate in the distribution of insurance products via platforms (including those of BigTechs) embedded (bundled) with other financial and non-financial services. In addition, in a broader context of Decentralised Finance (DEFI), Peer-to-Peer (P2P) insurance business models using digital platforms and different levels of decentralisation to interact with members with similar risks profiles have also emerged in several jurisdiction; although their significance in terms of gross written premiums is very limited to date, it is a matter that needs to be monitored.
EIOPA notes the opportunities and challenges arising from increasingly fragmented value chains and the platformisation of economy which will be reflected in the ESAs upcoming technical advice on digital finance to the European Commission, and will subsequently support any measures within its remit that may be needed to
encourage innovation and competition,
protect consumers,
safeguard financial stability
and ensure a level playing field.
ENHANCING THE SUPERVISORY CAPABILITIES OF EIOPA AND NCAS LEVERAGING ON TECHNOLOGY AND DATA FOR MORE EFFICIENT SUPERVISION AND REGULATORY COMPLIANCE Digital technologies can also help supervisors to implement more agile and efficient supervisory processes (commonly known as Suptech). They can support a continuous improvement of internal processes as well as business intelligence capabilities, including enhancing the analytical framework, the development of risk assessments and the publication of statistics. This can also include new capabilities for identifying and assessing conduct risks.
With its European perspective, EIOPA can play a key role by enhancing NCAs data analysis capabilities based on extensive and rich datasets and appropriate processing tools.
As outlined in its SupTech strategy and Data and IT strategy, EIOPA has the objective to promote its own transformation to become a digital, user-focused and data driven organisation that meets its strategic objectives effectively and efficiently. Several on-going projects are already in place to achieve this objective.
INCREASING THE UNDERSTANDING OF NEW TECHNOLOGIES BY SUPERVISORS IN CLOSE COOPERATION WITH STAKEHOLDERS Building supervisory capacity and convergence is a critical enabler for other benefits of digitalisation; without strong and convergent supervision, other benefits may be compromised. With the use of different tools available (innovation hubs, regulatory sandboxes, market monitoring, public consultations, desk-based reports etc.), supervisors seek to understand, engage and supervise increasingly technology-driven undertakings.
Closely cooperating with stakeholders with hands-on experience on the use of innovative tools has proofed to be useful tool to improve the knowledge by supervisors, and also for the stakeholders it is important to understand what are the supervisory expectations.
Certainly, the profile of the supervisors needs to evolve and they need to extend their knowledge into new areas and understand how new business models and value chains may impact undertakings and intermediaries both from a conduct and from a prudential perspective. Moreover, in view of the growing importance of new technologies and business models for insurance undertakings and pensions schemes, it is important to ensure that supervisors have access to relevant data about these developments in order to enable an evidence-based supervision.
EIOPA aims to continue incentivising the sharing of knowledge and experience amongst NCAs by organising InsurTech roundtables, workshops and seminars for supervisors as well as pursuing further potential deep-dive analysis on certain financial innovation topics. EIOPA will also further emphasise an evidence-based supervisory approach by developing a regular collection of harmonised data on digitalisation topics. EIOPA will also develop a stakeholder engagement strategy on digitalisation topics to identify those actors and areas where the cooperation should be reinforced.
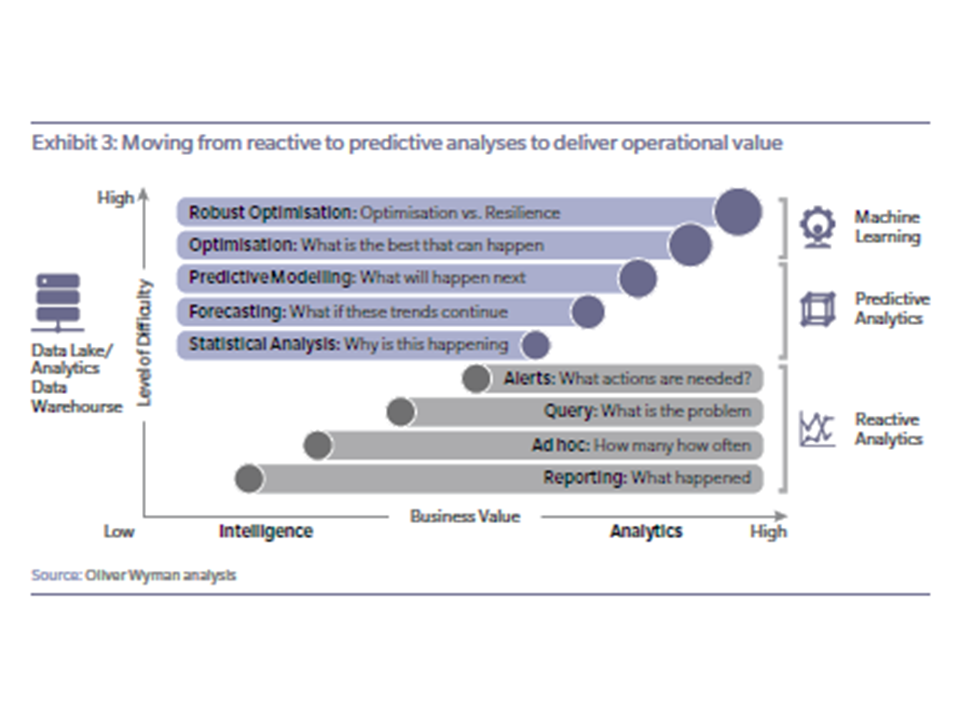
When it comes to being data-driven, organizations run the gamut with maturity levels. Most believe that data and analytics provide insights. But only one-third of respondents to a TDWI survey said they were truly data-driven, meaning they analyze data to drive decisions and actions.
Successful data-driven businesses foster a collaborative, goal-oriented culture. Leaders believe in data and are governance-oriented. The technology side of the business ensures sound data quality and puts analytics into operation. The data management strategy spans the full analytics life cycle. Data is accessible and usable by multiple people – data engineers and data scientists, business analysts and less-technical business users.
TDWI analyst Fern Halper conducted research of analytics and data professionals across industries and identified the following five best practices for becoming a data-driven organization.
1. Build relationships to support collaboration
If IT and business teams don’t collaborate, the organization can’t operate in a data-driven way – so eliminating barriers between groups is crucial. Achieving this can improve market performance and innovation; but collaboration is challenging. Business decision makers often don’t think IT understands the importance of fast results, and conversely, IT doesn’t think the business understands data management priorities. Office politics come into play.
But having clearly defined roles and responsibilities with shared goals across departments encourages teamwork. These roles should include: IT/architecture, business and others who manage various tasks on the business and IT sides (from business sponsors to DevOps).
2. Make data accessible and trustworthy
Making data accessible – and ensuring its quality – are key to breaking down barriers and becoming data-driven. Whether it’s a data engineer assembling and transforming data for analysis or a data scientist building a model, everyone benefits from trustworthy data that’s unified and built around a common vocabulary.
As organizations analyze new forms of data – text, sensor, image and streaming – they’ll need to do so across multiple platforms like data warehouses, Hadoop, streaming platforms and data lakes. Such systems may reside on-site or in the cloud. TDWI recommends several best practices to help:
Establish a data integration and pipeline environment with tools that provide federated access and join data across sources. It helps to have point-and-click interfaces for building workflows, and tools that support ETL, ELT and advanced specifications like conditional logic or parallel jobs.
Manage, reuse and govern metadata – that is, the data about your data. This includes size, author, database column structure, security and more.
Provide reusable data quality tools with built-in analytics capabilities that can profile data for accuracy, completeness and ambiguity.
3. Provide tools to help the business work with data
From marketing and finance to operations and HR, business teams need self-service tools to speed and simplify data preparation and analytics tasks. Such tools may include built-in, advanced techniques like machine learning, and many work across the analytics life cycle – from data collection and profiling to monitoring analytical models in production.
These “smart” tools feature three capabilities:
Automation helps during model building and model management processes. Data preparation tools often use machine learning and natural language processing to understand semantics and accelerate data matching.
Reusability pulls from what has already been created for data management and analytics. For example, a source-to-target data pipeline workflow can be saved and embedded into an analytics workflow to create a predictive model.
Explainability helps business users understand the output when, for example, they’ve built a predictive model using an automated tool. Tools that explain what they’ve done are ideal for a data-driven company.
4. Consider a cohesive platform that supports collaboration and analytics
As organizations mature analytically, it’s important for their platform to support multiple roles in a common interface with a unified data infrastructure. This strengthens collaboration and makes it easier for people to do their jobs.
For example, a business analyst can use a discussion space to collaborate with a data scientist while building a predictive model, and during testing. The data scientist can use a notebook environment to test and validate the model as it’s versioned and metadata is captured. The data scientist can then notify the DevOps team when the model is ready for production – and they can use the platform’s tools to continually monitor the model.
5. Use modern governance technologies and practices
Governance – that is, rules and policies that prescribe how organizations protect and manage their data and analytics – is critical in learning to trust data and become data-driven. But TDWI research indicates that one-third of organizations don’t govern their data at all. Instead, many focus on security and privacy rules. Their research also indicates that fewer than 20 percent of organizations do any type of analytics governance, which includes vetting and monitoring models in production.
Decisions based on poor data – or models that have degraded – can have a negative effect on the business. As more people across an organization access data and build models, and as new types of data and technologies emerge (big data, cloud, stream mining), data governance practices need to evolve. TDWI recommends three features of governance software that can strengthen your data and analytics governance:
Data catalogs, glossaries and dictionaries. These tools often include sophisticated tagging and automated procedures for building and keeping catalogs up to date – as well as discovering metadata from existing data sets.
Data lineage. Data lineage combined with metadata helps organizations understand where data originated and track how it was changed and transformed.
Model management. Ongoing model tracking is crucial for analytics governance. Many tools automate model monitoring, schedule updates to keep models current and send alerts when a model is degrading.
In the future, organizations may move beyond traditional governance council models to new approaches like agile governance, embedded governance or crowdsourced governance.
But involving both IT and business stakeholders in the decision-making process – including data owners, data stewards and others – will always be key to robust governance at data-driven organizations.
There’s no single blueprint for beginning a data analytics project – never mind ensuring a successful one.
However, the following questions help individuals and organizations frame their data analytics projects in instructive ways. Put differently, think of these questions as more of a guide than a comprehensive how-to list.
1. Is this your organization’s first attempt at a data analytics project?
When it comes to data analytics projects, culture matters. Consider Netflix, Google and Amazon. All things being equal, organizations like these have successfully completed data analytics projects. Even better, they have built analytics into their cultures and become data-driven businesses.
As a result, they will do better than neophytes. Fortunately, first-timers are not destined for failure. They should just temper their expectations.
2. What business problem do you think you’re trying to solve?
This might seem obvious, but plenty of folks fail to ask it before jumping in. Note here how I qualified the first question with “do you think.” Sometimes the root cause of a problem isn’t what we believe it to be; in other words, it’s often not what we at first think.
In any case, you don’t need to solve the entire problem all at once by trying to boil the ocean. In fact, you shouldn’t take this approach. Project methodologies (like agile) allow organizations to take an iterative approach and embrace the power of small batches.
3. What types and sources of data are available to you?
Most if not all organizations store vast amounts of enterprise data. Looking at internal databases and data sources makes sense. Don’t make the mistake of believing, though, that the discussion ends there.
External data sources in the form of open data sets (such as data.gov) continue to proliferate. There are easy methods for retrieving data from the web and getting it back in a usable format – scraping, for example. This tactic can work well in academic environments, but scraping could be a sign of data immaturity for businesses. It’s always best to get your hands on the original data source when possible.
Caveat: Just because the organization stores it doesn’t mean you’ll be able to easily access it. Pernicious internal politics stifle many an analytics endeavor.
4. What types and sources of data are you allowed to use?
With all the hubbub over privacy and security these days, foolish is the soul who fails to ask this question. As some retail executives have learned in recent years, a company can abide by the law completely and still make people feel decidedly icky about the privacy of their purchases. Or, consider a health care organization – it may not technically violate the Health Insurance Portability and Accountability Act of 1996 (HIPAA), yet it could still raise privacy concerns.
Another example is the GDPR. Adhering to this regulation means that organizations won’t necessarily be able to use personal data they previously could use – at least not in the same way.
5. What is the quality of your organization’s data?
Common mistakes here include assuming your data is complete, accurate and unique (read: nonduplicate). During my consulting career, I could count on one hand the number of times a client handed me a “perfect” data set. While it’s important to cleanse your data, you don’t need pristine data just to get started. As Voltaire said, “Perfect is the enemy of good.”
6. What tools are available to extract, clean, analyze and present the data?
This isn’t the 1990s, so please don’t tell me that your analytic efforts are limited to spreadsheets. Sure, Microsoft Excel works with structured data – if the data set isn’t all that big. Make no mistake, though: Everyone’s favorite spreadsheet program suffers from plenty of limitations, in areas like:
Handling semistructured and unstructured data.
Tracking changes/version control.
Dealing with size restrictions.
Ensuring governance.
Providing security.
For now, suffice it to say that if you’re trying to analyze large, complex data sets, there are many tools well worth exploring. The same holds true for visualization. Never before have we seen such an array of powerful, affordable and user-friendly tools designed to present data in interesting ways.
Caveat 1: While software vendors often ape each other’s features, don’t assume that each application can do everything that the others can.
Caveat 2: With open source software, remember that “free” software could be compared to a “free” puppy. To be direct: Even with open source software, expect to spend some time and effort on training and education.
7. Do your employees possess the right skills to work on the data analytics project?
The database administrator may well be a whiz at SQL. That doesn’t mean, though, that she can easily analyze gigabytes of unstructured data. Many of my students need to learn new programs over the course of the semester, and the same holds true for employees. In fact, organizations often find that they need to:
Provide training for existing employees.
Hire new employees.
Contract consultants.
Post the project on sites such as Kaggle.
All of the above.
Don’t assume that your employees can pick up new applications and frameworks 15 minutes at a time every other week. They can’t.
8. What will be done with the results of your analysis?
A company routinely spent millions of dollars recruiting MBAs at Ivy League schools only to see them leave within two years. Rutgers MBAs, for their part, stayed much longer and performed much better.
Despite my findings, the company continued to press on. It refused to stop going to Harvard, Cornell, etc. because of vanity. In his own words, the head of recruiting just “liked” going to these schools, data be damned.
Food for thought: What will an individual, group, department or organization do with keen new insights from your data analytics projects? Will the result be real action? Or will a report just sit in someone’s inbox?
9. What types of resistance can you expect?
You might think that people always and willingly embrace the results of data-oriented analysis. And you’d be spectacularly wrong.
Case in point: Major League Baseball (MLB) umpires get close ball and strike calls wrong more often than you’d think. Why wouldn’t they want to improve their performance when presented with objective data? It turns out that many don’t. In some cases, human nature makes people want to reject data and analytics that contrast with their world views. Years ago, before the subscription model became wildly popular, some Blockbuster executives didn’t want to believe that more convenient ways to watch movies existed.
Caveat: Ignore the power of internal resistance at your own peril.
10. What are the costs of inaction?
Sure, this is a high-level query and the answers depend on myriad factors.
For instance, a pharma company with years of patent protection will respond differently than a startup with a novel idea and competitors nipping at its heels. Interesting subquestions here include:
Do the data analytics projects merely confirm what we already know?
Do the numbers show anything conclusive?
Could we be capturing false positives and false negatives?
Think about these questions before undertaking data analytics projects Don’t take the queries above as gospel. By and large, though, experience proves that asking these questions frames the problem well and sets the organization up for success – or at least minimizes the chance of a disaster.
Most organizations understand the importance of data governance in concept. But they may not realize all the multifaceted, positive impacts of applying good governance practices to data across the organization. For example, ensuring that your sales and marketing analytics relies on measurably trustworthy customer data can lead to increased revenue and shorter sales cycles. And having a solid governance program to ensure your enterprise data meets regulatory requirements could help you avoid penalties.
Companies that start data governance programs are motivated by a variety of factors, internal and external. Regardless of the reasons, two common themes underlie most data governance activities: the desire for high-quality customer information, and the need to adhere to requirements for protecting and securing that data.
What’s the best way to ensure you have accurate customer data that meets stringent requirements for privacy and security?
For obvious reasons, companies exert significant effort using tools and third-party data sets to enforce the consistency and accuracy of customer data. But there will always be situations in which the managed data set cannot be adequately synchronized and made consistent with “real-world” data. Even strictly defined and enforced internal data policies can’t prevent inaccuracies from creeping into the environment.
Why you should move beyond a conventional approach to data governance?
When it comes to customer data, the most accurate sources for validation are the customers themselves! In essence, every customer owns his or her information, and is the most reliable authority for ensuring its quality, consistency and currency. So why not develop policies and methods that empower the actual owners to be accountable for their data?
Doing this means extending the concept of data governance to the customers and defining data policies that engage them to take an active role in overseeing their own data quality. The starting point for this process fits within the data governance framework – define the policies for customer data validation.
A good template for formulating those policies can be adapted from existing regulations regarding data protection. This approach will assure customers that your organization is serious about protecting their data’s security and integrity, and it will encourage them to actively participate in that effort.
Examples of customer data engagement policies
Data protection defines the levels of protection the organization will use to protect the customer’s data, as well as what responsibilities the organization will assume in the event of a breach. The protection will be enforced in relation to the customer’s selected preferences (which presumes that customers have reviewed and approved their profiles).
Data access control and security define the protocols used to control access to customer data and the criteria for authenticating users and authorizing them for particular uses.
Data use describes the ways the organization will use customer data.
Customer opt-in describes the customers’ options for setting up the ways the organization can use their data.
Customer data review asserts that customers have the right to review their data profiles and to verify the integrity, consistency and currency of their data. The policy also specifies the time frame in which customers are expected to do this.
Customer data update describes how customers can alert the organization to changes in their data profiles. It allows customers to ensure their data’s validity, integrity, consistency and currency.
Right-to-use defines the organization’s right to use the data as described in the data use policy (and based on the customer’s selected profile options). This policy may also set a time frame associated with the right-to-use based on the elapsed time since the customer’s last date of profile verification.
The goal of such policies is to establish an agreement between the customer and the organization that basically says the organization will protect the customer’s data and only use it in ways the customer has authorized – in return for the customer ensuring the data’s accuracy and specifying preferences for its use. This model empowers customers to take ownership of their data profile and assume responsibility for its quality.
Clearly articulating each party’s responsibilities for data stewardship benefits both the organization and the customer by ensuring that customer data is high-quality and properly maintained. Better yet, recognize that the value goes beyond improved revenues or better compliance.
Empowering customers to take control and ownership of their data just might be enough to motivate self-validation.
Historically, the insurance industry has collected vast amounts of data relevant to their customers, claims, and so on. This can be unstructured data in the form of PDFs, text documents, images, and videos, or structured data that has been organized for big data analytics.
As with other industries, the existence of such a trove of data in the insurance industry led many of the larger firms to adopt big data analytics and techniques to find patterns in the data that might reveal insights that drive business value.
Any such big data applications may require several steps of data management, including collection, cleansing, consolidation, and storage. Insurance firms that have worked with some form of big data analytics in the past might have access to structured data which can be ingested by AI algorithms with little additional effort on the part of data scientists.
The insurance industry might be ripe for AI applications due to the availability of vast amounts of historical data records and the existence of large global companies with the resources to implement complex AI projects. The data being collected by these companies comes from several channels and in different formats, and AI search and discovery projects in the space require several initial steps to organize and manage data.
Radim Rehurek, who earned his PhD in Computer Science from the Masaryk University Brno and founded RARE Technologies, points out:
« A majority of the data that insurance firms collect is likely unstructured to some degree. This poses several challenges to insurance companies in terms of collecting and structuring data, which is key to the successful implementation of AI systems. »
Giacomo Domeniconi, a post-doctoral researcher at IBM Watson TJ Research Center and Adjunct Professor for the course “High-Performance Machine Learning” at New York University, mentions structuring the data as the largest challenge for businesses:
“Businesses need to structure their information and create labeled datasets, which can be used to train the AI system. Yet creating this labeled dataset might be very challenging apply AI and in most cases would involve manually labeling a part of the data using the expertise of a specialist in the domain.”
Businesses face many challenges in terms of collecting and structuring their data, which is key to the successful implementation of AI systems. An AI application is only as good as the data it consumes.
Natural language processing (NLP) and machine learning models often need to be trained on large volumes of data. Data scientists tweak these models to improve their accuracy.
This is a process that might last several months from start to finish, even in cases where the model is being taught relatively rudimentary tasks, such as identifying semantic trends in an insurance company’s internal documentation.
Most AI systems necessarily require the data to be input into an AI system in a structured format. Businesses would need to collect, clean, and organize their data to meet these requirements.
Although creating NLP and machine learning models to solve real-world business problems is by itself a challenging task, this process cannot be started without a plan for organizing and structuring enough data for these models to operate at reasonable accuracy levels.
Large insurance firms might need to think about how their data at different physical locations across the world might be affected by local data regulations or differences in data storage legacy systems at each location. Even with all the data being made accessible, businesses would find that data might still need to be scrubbed to remove any incorrect, incomplete, improperly formatted, duplicate, or outlying data. Businesses would also find that in some cases regulations might mandate the signing of data sharing agreements between the involved parties or data might need to be moved to locations where it can be analyzed. Since the data is highly voluminous, moving the data accurately can prove to be a challenge by itself.
Data processing has historically been at the very core of the business of insurance undertakings, which is rooted strongly in data-led statistical analysis. Data has always been collected and processed to
inform underwriting decisions,
price policies,
settle claims
and prevent fraud.
There has long been a pursuit of more granular data-sets and predictive models, such that the relevance of Big Data Analytics (BDA) for the sector is no surprise.
In view of this, and as a follow-up of the Joint Committee of the European Supervisory Authorities (ESAs) cross-sectorial report on the use of Big Data by financial institutions,1 the European Insurance and Occupational Pensions Authority (EIOPA) decided to launch a thematic review on the use of BDA specifically by insurance firms. The aim is to gather further empirical evidence on the benefits and risks arising from BDA. To keep the exercise proportionate, the focus was limited to motor and health insurance lines of business. The thematic review was officially launched during the summer of 2018.
A total of 222 insurance undertakings and intermediaries from 28 jurisdictions have participated in the thematic review. The input collected from insurance undertakings represents approximately 60% of the total gross written premiums (GWP) of the motor and health insurance lines of business in the respective national markets, and it includes input from both incumbents and start-ups. In addition, EIOPA has collected input from its Members and Observers, i.e. national competent authorities (NCAs) from the European Economic Area, and from two consumers associations.
The thematic review has revealed a strong trend towards increasingly data-driven business models throughout the insurance value chain in motor and health insurance:
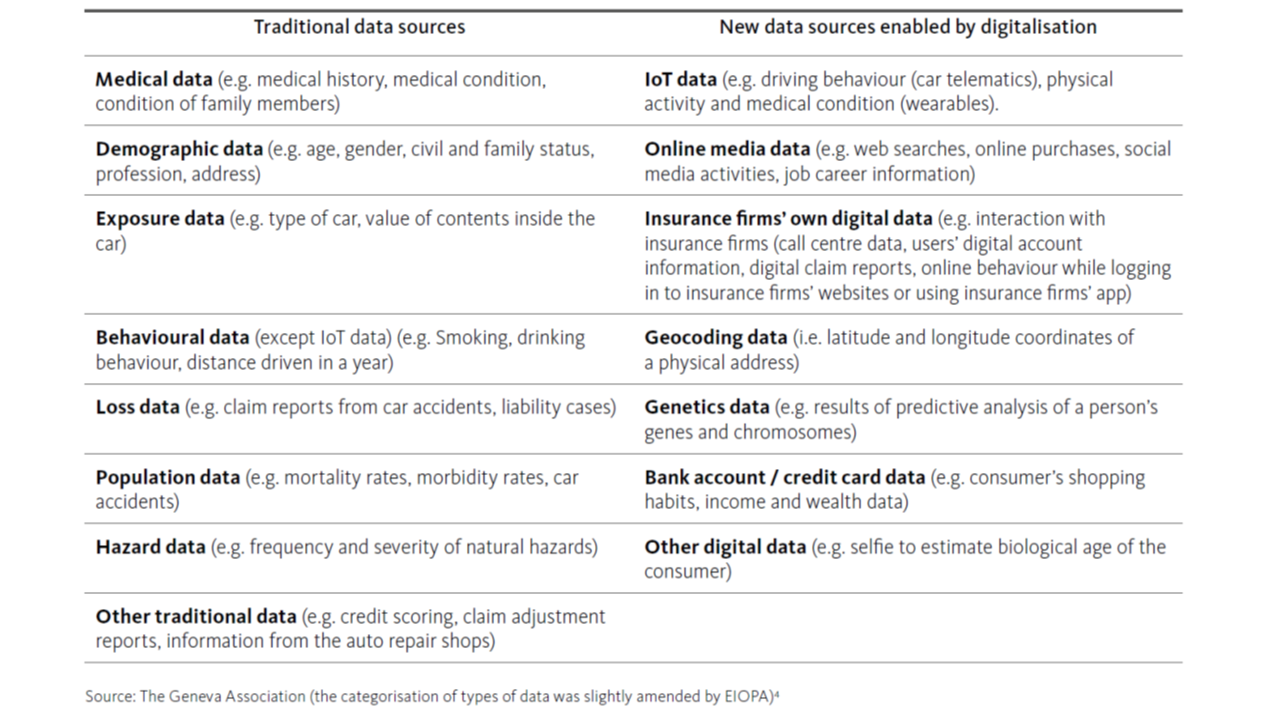
Traditional data sources such as demographic data or exposure data are increasingly combined (not replaced) with new sources like online media data or telematics data, providing greater granularity and frequency of information about consumer’s characteristics, behaviour and lifestyles. This enables the development of increasingly tailored products and services and more accurate risk assessments.
The use of data outsourced from third-party data vendors and their corresponding algorithms used to calculate credit scores, driving scores, claims scores, etc. is relatively extended and this information can be used in technical models.
BDA enables the development of new rating factors, leading to smaller risk pools and a larger number of them. Most rating factors have a causal link while others are perceived as being a proxy for other risk factors or wealth / price elasticity of demand.
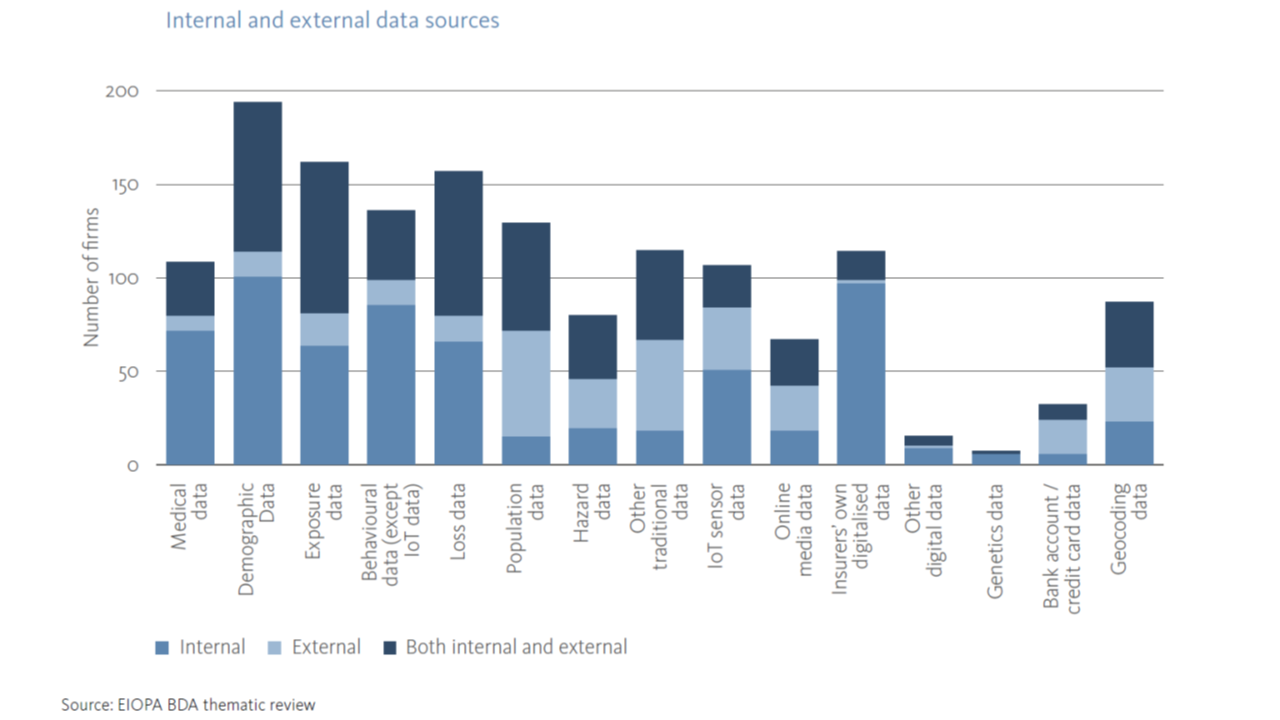
BDA tools such as such as artificial intelligence (AI) or machine learning (ML) are already actively used by 31% of firms, and another 24% are at a proof of concept stage. Models based on these tools are often cor-relational and not causative, and they are primarily used on pricing and underwriting and claims management.
Cloud computing services, which reportedly represent a key enabler of agility and data analytics, are already used by 33% of insurance firms, with a further 32% saying they will be moving to the cloud over the next 3 years. Data security and consumer protection are key concerns of this outsourcing activity.
Up take of usage-based insurance products will gradually continue in the following years, influenced by developments such as increasingly connected cars, health wearable devices or the introduction of 5G mobile technology. Roboadvisors and specially chatbots are also gaining momentum within consumer product and service journeys.
There is no evidence as yet that an increasing granularity of risk assessments is causing exclusion issues for high-risk consumers, although firms expect the impact of BDA to increase in the years to come.
In view of the evidence gathered from the different stake-holders, EIOPA considers that there are many opportunities arising from BDA, both for the insurance industry as well as for consumers. However, and although insurance firms generally already have in place or are developing sound data governance arrangements, there are also risks arising from BDA that need to be further addressed in practice. Some of these risks are not new, but their significance is amplified in the context of BDA. This is particularly the case regarding ethical issues with the fairness of the use of BDA, as well as regarding the
accuracy,
transparency,
auditability,
and explainability
of certain BDA tools such as AI and ML.
Going forward, in 2019 EIOPA’s InsurTech Task Force will conduct further work in these two key areas in collaboration with the industry, academia, consumer associations and other relevant stakeholders. The work being developed by the Joint Committee of the ESAs on AI as well as in other international fora will also be taken into account. EIOPA will also explore third-party data vendor issues, including transparency in the use of rating factors in the context of the EU-US insurance dialogue. Furthermore, EIOPA will develop guidelines on the use of cloud computing by insurance firms and will start a new workstream assessing new business models and ecosystems arising from InsurTech. EIOPA will also continue its on-going work in the area of cyber insurance and cyber security risks.
Technology waits for no one. And those who strike first will have an advantage. The steady decline in business profitability across multiple industries threatens to erode future investment, innovation and shareholder value. Fortunately, the emergence of artificial intelligence (AI) can help kick-start profitability. Accenture research shows that AI has the potential to boost rates of profitability by an average of 38 percent by 2035 and lead to an economic boost of US$14 trillion across 16 industries in 12 economies by 2035.
Driven by these economic forces, the age of digital transformation is in full swing. Today we can’t be “digital to the core” if we don’t leverage all new data sources – unstructured, dark data and thirty party sources. Similarly, we have to take advantage of the convergence of AI and analytics to uncover previously hidden insights. But, with the increasing use of AI, we also have to be responsible and take into account the social implications.
Finding answers to the biggest questions starts with data, and ensuring you are capitalizing on the vast data sources available within your own business. Thanks to the power of AI/machine learning and advanced algorithms, we have moved from the era of big data to the era of ALL data, and that is helping clients create a more holistic view of their customer and more operational efficiencies.
Embracing the convergence of AI and analytics is crucial to success in our digital transformation. Together,
AI-powered analytics unlock tremendous value from data that was previously hidden or unreachable,
changing the way we interact with people and technology,
improving the way we make decisions, and giving way to new agility and opportunities.
While businesses are still in the infancy of tapping into the vast potential of these combined technologies, now is the time to accelerate. But to thrive, we need to be pragmatic in finding the right skills and partners to guide our strategy.
Finally, whenever we envision the possibilities of AI, we should consider the responsibility that comes with it. Trust in the digital era or “responsible AI” cannot be overlooked. Explainable AI and AI transparency are critical, particularly in such areas as
financial services,
healthcare,
and life sciences.
The new imperative of our digital transformation is to balance intelligent technology and human ingenuity to innovate every facet of business and become a smarter enterprise.
The exponential growth of data underlying the strategic imperative of enterprise digital transformation has created new business opportunities along with tremendous challenges. Today, we see organizations of all shapes and sizes embarking on digital transformation. As uncovered in Corinium Digital’s research, the primary drivers of digital transformation are those businesses focused on addressing increasing customer expectations and implementing efficient internal processes.
Data is at the heart of this transformation and provides the fuel to generate meaningful insights. We have reached the tipping point where all businesses recognize they cannot compete in a digital age using analog-era legacy solutions and architectures. The winners in the next phase of business will be those enterprises that obtain a clear handle on the foundations of modern data management, specifically the nexus of
data quality,
cloud,
and artificial intelligence (AI).
While most enterprises have invested in on-premises data warehouses as the backbone of their analytic data management practices, many are shifting their new workloads to the cloud. The proliferation of new data types and sources is accelerating the development of data lakes with aspirations of gaining integrated analytics that can accelerate new business opportunities. We found in the research that over 60% of global enterprises are now investing in a hybrid, multi-cloud strategy with both data from cloud environments such as Microsoft Azure along with existing on-premises infrastructures. Hence, this hybrid, multicloud strategy will need to correlate with their investments in data analytics, and it will become imperative to manage data seamlessly across all platforms. At Paxata, our mission is to give everyone the power to intelligently profile and transform data into consumable information at the speed of thought. To empower everyone, not just technical users, to prepare their data and make it ready for analytics and decision making.
The first step in making this transition is to eliminate the bottlenecks of traditional IT-led data management practices through AI-powered automation.
Second, you need to apply modern data preparation and data quality principles and technology platforms to support both analytical and operational use cases.
Thirdly, you need a technology infrastructure that embraces the hybrid, multi-cloud world. Paxata sits right at the center stage of this new shift, helping enterprises profile and transform complex data types in highvariety, high-volume environments. As such, we’re excited about partnering with Accenture and Microsoft to accelerate businesses with our ability to deliver modern analytical and operational platforms to address today’s digital transformation requirements.
Artificial intelligence is causing two major revolutions simultaneously among developers and enterprises. These revolutions will drive the technology decisions for the next decade. Developers are massively embracing AI. As a platform company, Microsoft is focused on enabling developers to make the shift to the next app development pattern, driven by the intelligent cloud and intelligent edge.
AI is the runtime that will power the apps of the future. At the same time, enterprises are eager to adopt and integrate AI. Cloud and AI are the most requested topics in Microsoft Executive Briefing Centers. AI is changing how companies serve their customers, run their operations, and innovate.
Ultimately, every business process in every industry will be redefined in profound ways. If it used to be true that “software was eating the world,” it is now true to say that “AI is eating software”. A new competitive differentiator is emerging: how well an enterprise exploits AI to reinvent and accelerate its processes, value chain and business models. Enterprises need a strategic partner who can help them transform their organization with AI. Microsoft is emerging as a solid AI leader as it is in a unique position to address both revolutions. Our strength and differentiation lie in the combination of multiple assets:
Azure AI services that bring AI to every developer. Over one million developers are accessing our pre-built and customizable AI services. We have the most comprehensive solution for building bots, combined with a powerful platform for Custom AI development with Azure Machine Learning that spans the entire AI development lifecycle, and a market leading portfolio of pre-built cognitive services that can be readily attached to applications.
A unique cloud infrastructure including CPU, GPU, and soon FPGA, makes Azure the most reliable, scalable and fastest cloud to run AI workloads.
Unparalleled tools. Visual Studio, used by over 6 million developers, is the most preferred tool in the world for application development. Visual Studio and Visual Studio Code are powerful “front doors” through which to attract developers seeking to add AI to their applications.
Ability to add AI to the edge. We enable developers, through our tools and services, to develop an AI model and deploy that model anywhere. Through our support for ONNX – the open source representation for AI models in partnership with Facebook, Amazon, IBM and others – as well as for generic containers, we allow developers to run their models on the IoT edge and leverage the entire IoT solution from Azure.
But the competition to win enterprises is not only played in the platform battlefield, enterprises are demanding solutions. Microsoft AI solutions provide turnkey implementations for customers who want to transform their core processes with AI. Our unique combination of IP and consulting services address common scenarios such as business agents, sales intelligence or marketing intelligence. As our solutions are built on top of our compelling AI platform, unlike ourcompetitors, our customers are not locked in to any one consulting provider, they remain in full control of their data and can extend the scenarios or target new scenarios themselves or through our rich partner ecosystem.
The evolution of financial technology (FinTech) is reshaping the broader financial services industry. Technology is now disrupting the traditionally more conservative insurance industry, as the rise of InsurTech revolutionises how we think about insurance distribution.
Moreover, insurance companies are improving their operating models, upgrading their propositions, and developing innovative new products to reshape the insurance industry as a whole.
Five key technologies are driving the change today:
Cloud computing
The Internet of Things (including telematics)
Big data
Artificial intelligence
Blockchain
This report examines these technologies’ potential to create value in the insurance industry. It also examines how technology providers could create new income streams and take advantage of economies of scale by offering their technological backbones to participants in the insurance industry and beyond.
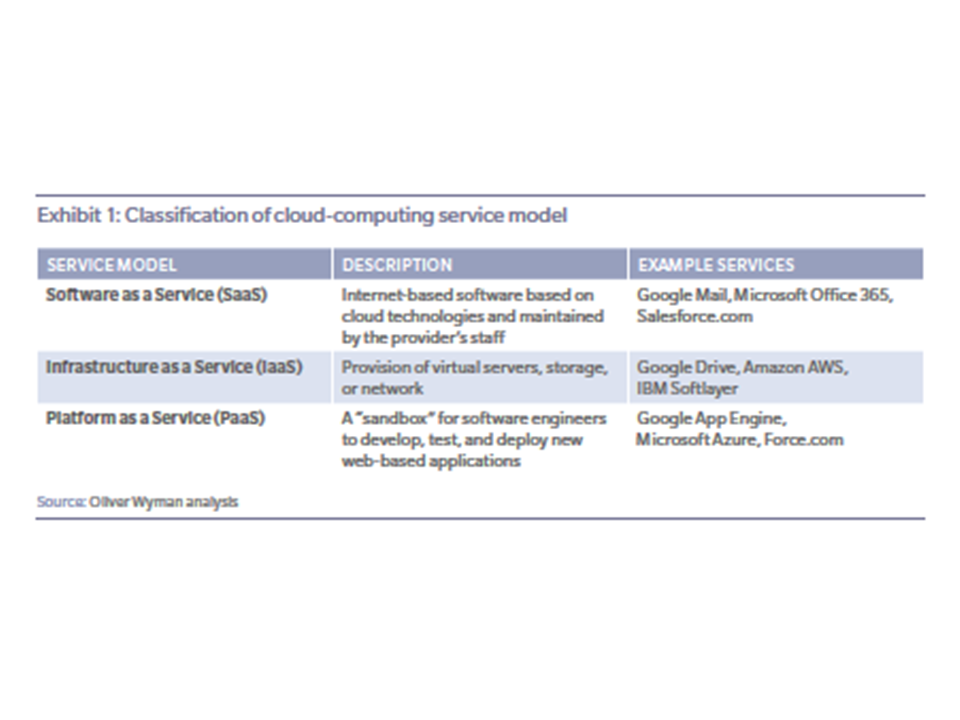
Cloud computing refers to storing, managing, and processing data via a network of remote servers, instead of locally on a server or personal computer. Key enablers of cloud computing include the availability of high-capacity networks and service-oriented architecture. The three core characteristics of a cloud service are:
Virtualisation: The service is based on hardware that has been virtualised
Scalability: The service can scale on demand, with additional capacity brought online within minutes
Demand-driven: The client pays for the services as and when they are needed
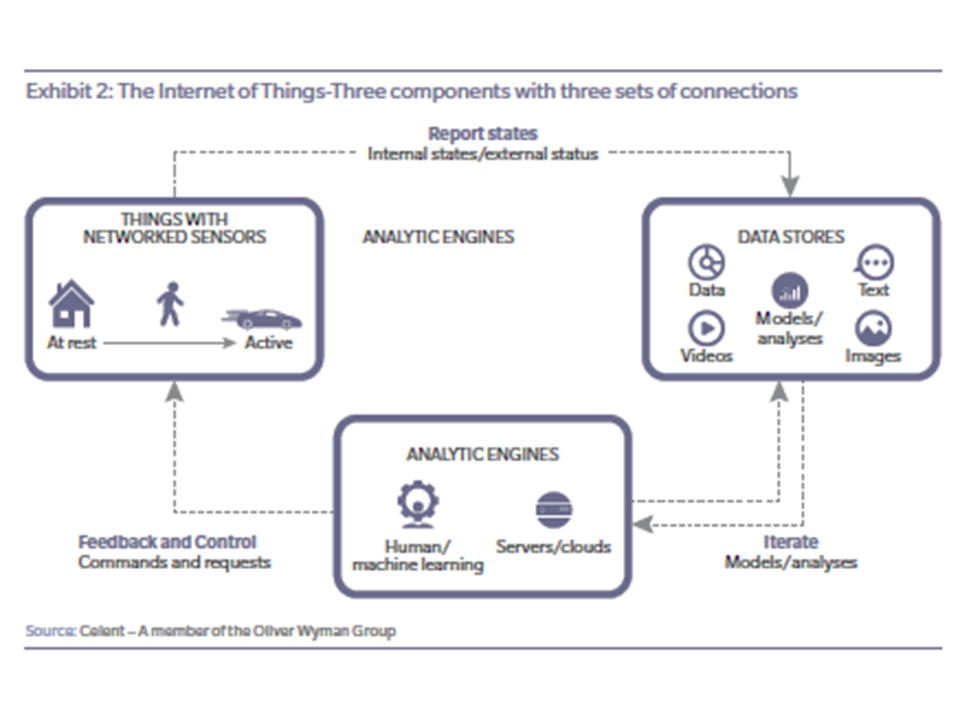
Telematics is the most common form of the broader Internet of Things (IoT). The IoT refers to the combination of physical devices, vehicles, buildings and other items embedded with electronics, software, sensors, actuators, and network connectivity that enable these physical objects to collect and exchange data.
The IoT has evolved from the convergence of
wireless technologies,
micro-electromechanical systems,
and the Internet.
This convergence has helped remove the walls between operational technology and information technology, allowing unstructured, machine-generated data to be analysed for insights that will drive improvements.
Big data refers to data sets that are so large or complex that traditional data processing application software is insufficient to deal with them. A definition refers to the “five V” key challenges for big data in insurance:
Volume: As sensors cost less, the amount of information gathered will soon be measured
in exabytes
Velocity: The speed at which data is collected, analysed, and presented to users
Variety: Data can take many forms, such as structured, unstructured, text or multimedia. It can come from internal and external systems and sources, including a variety
of devices
Value: Information provided by data about aspects of the insurance business, such as customers and risks
Veracity: Insurance companies ensure the accuracy of their plethora of data
Modern analytical methods are required to process these sets of information. The term “big data has evolved to describe the quantity of information analysed to create better outcomes, business improvements, and opportunities that leverage all available data. As a result, big data is not limited to the challenges thrown up by the five Vs. Today there are two key aspects to big data:
Data: This is more-widely available than ever because of the use of apps, social media, and the Internet of Things
Analytics: Advanced analytic tools mean there are fewer restrictions to working with big data
The understanding of Artificial Intelligence AI has evolved over time. In the beginning, AI was perceived as machines mimicking the cognitive functions that humans associate with other human minds, such as learning and problem solving. Today, we rather refer to the ability of machines to mimic human activity in a broad range of circumstances. In a nutshell, artificial intelligence is the broader concept of machines being able to carry out tasks in a way that we would consider smart or human.
Therefore, AI combines the reasoning already provided by big data capabilities such as machine learning with two additional capabilities:
Imitation of human cognitive functions beyond simple reasoning, such as natural language processing and emotion sensing
Orchestration of these cognitive components with data and reasoning
A third layer is pre-packaging generic orchestration capabilities for specific applications. The most prominent such application today are bots. At a minimum, bots orchestrate natural language processing, linguistic technology, and machine learning to create systems which mimic interactions with human beings in certain domains. This is done in such a way that the customer does not realise that the counterpart is not human.
Blockchainis a distributed ledger technology used to store static records and dynamic transaction data distributed across a network of synchronised, replicated databases. It establishes trust between parties without the use of a central intermediary, removing frictional costs and inefficiency.
From a technical perspective, blockchain is a distributed database that maintains a continuously growing list of ordered records called blocks. Each block contains a timestamp and a link to a previous block. Blockchains have been designed to make it inherently difficult to modify their data: Once recorded, the data in a block cannot be altered retroactively. In addition to recording transactions, blockchains can also contain a coded set of instructions that will self-execute under a pre-specified set of conditions. These automated workflows, known as smart contracts, create trust between a set of parties, as they rely on pre-agreed data sources and and require not third-party to execute them.
Blockchain technology in its purest form has four key characteristics:
Decentralisation: No single individual participant can control the ledger. The ledger
lives on all computers in the network
Transparency: Information can be viewed by all participants on the network, not just
those involved in the transaction
Immutability: Modifying a past record would require simultaneously modifying every
other block in the chain, making the ledger virtually incorruptible
Singularity: The blockchain provides a single version of a state of affairs, which is
updated simultaneously across the network
Oliver Wyman, ZhongAn Insurance and ZhongAn Technology – a wholly owned subsidiary of ZhongAn insurance and China’s first online-only insurer – are jointly publishing this report to analyse the insurance technology market and answer the following questions:
Which technologies are shaping the future of the insurance industry? (Chapter 2)
What are the applications of these technologies in the insurance industry? (Chapter 3)
What is the potential value these applications could generate? (Chapter 3)
How can an insurer with strong technology capabilities monetise its technologies?
(Chapter 4)
Who is benefiting from the value generated by these applications? (Chapter 5)