Executive summary
International Financial Reporting Standard (IFRS) 17, the first comprehensive global accounting standard for insurance products, is due to be implemented in 2023, and is the latest standard developed by the International Accounting Standards Board (IASB) in its push for international accounting standards.
IFRS 17, following other standards such as IFRS 9 and Current Expected Credit Losses (CECL), is the latest move toward ‘risk-ware accounting’, a framework that aims to incorporate financial and non-financial risk into accounting valuation.
As a principles-based standard, IFRS 17 provides room for different interpretations, meaning that insurers have choices to make about how to comply. The explicit integration of financial and non-financial risk has caused much discussion about the unprecedented and distinctive modeling challenges that IFRS 17 presents. These could cause ‘tunnel vision’ among insurers when it comes to how they approach compliance.
But all stages of IFRS 17 compliance are important, and each raises distinct challenges. By focusing their efforts on any one aspect of the full compliance value chain, insurers can risk failing to adequately comply. In the case of IFRS 17, it is not necessarily accidental non-compliance that is at stake, but rather the sub-optimal presentation of the business’ profits.
To achieve ‘ideal’ compliance, firms need to focus on the logistics of reporting as much as on the mechanics of modeling. Effective and efficient reporting comprises two elements: presentation and disclosure. Reporting is the culmination of the entire compliance value chain, and decisions made further up the chain can have a significant impact on the way that value is presented. Good reporting is achieved through a mixture of technology and accounting policy, and firms should follow several strategies in achieving this:
- Anticipate how the different IFRS 17 measurement models will affect balance sheet volatility.
- Understand the different options for disclosure, and which approach is best for specific institutional needs.
- Streamline IFRS 17 reporting with other reporting duties.
- Where possible, aim for collaborative report generation while maintaining data integrity.
- Explore and implement technology that can service IFRS 17’s technical requirements for financial reporting.
- Store and track data on a unified platform.
In this report we focus on the challenges associated with IFRS 17 reporting, and consider solutions to those challenges from the perspectives of accounting policy and technology implementation. And in highlighting the reporting stage of IFRS 17 compliance, we focus specifically on how decisions about the presentation of data can dictate the character of final disclosure.
- Introduction: more than modeling
IFRS 17 compliance necessitates repeated stochastic calculations to capture financial and nonfinancial risk (especially in the case of long-term insurance contracts). Insurance firms consistently identify modeling and data management as the challenges they most anticipate having to address in their efforts to comply. Much of the conversation and ‘buzz’ surrounding IFRS 17 has therefore centered on its modeling requirements, and in particular the contractual service margin (CSM) calculation.
But there is always a danger that firms will get lost in the complexity of compliance and forget the aim of IFRS 17. Although complying with IFRS 17 involves multiple disparate process elements and activities, it is still essentially an accounting
standard. First and foremost its aim is to ensure the transparent and comparable disclosure of the value of insurance services.
So while IFRS 17 calculations are crucial, they are just one stage in the compliance process, and ultimately enable the intended outcome: reporting.
Complying with the modeling requirements of IFRS 17 should not create ‘compliance tunnel vision’ at the expense of the presentation and disclosure of results. Rather, presentation and disclosure are the culmination of the IFRS 17 compliance process flow and are key elements of effective reporting (see Figure 1).

- Developing an IFRS 17 accounting policy
A key step in developing reporting compliance is having an accounting policy tailored to a firm’s specific interaction with IFRS 17. Firms have decisions to make about how to comply, together with considerations of the knock-on effects IFRS 17 will have on the presentation of their comprehensive statements of income.
There are a variety of considerations: in some areas IFRS 17 affords a degree of flexibility; in others it does not. Areas that will substantially affect the appearance of firms’ profits are:
• The up-front recognition of loss and the amortization of profit.
• The new unit of account.
• The separation of investment components from insurance services.
• The recognition of interest rate changes under the general measurement model (GMM).
• Deferred acquisition costs under the premium allocation approach (PAA).
As a principles-based standard, IFRS 17 affords a degree of flexibility in how firms approach valuation. One of its aims is to insure that entity specific risks and diverse contract features are adequately reflected in valuations, while still safeguarding reporting comparability. This flexibility also gives firms some degree of control over the way that value and risk are portrayed in financial statements. However, some IFRS 17 stipulations will lead to inevitable accounting mismatches and balance-sheet volatility.
Accounting policy impacts and choices – Balance sheet volatility
One unintended consequence of IFRS 17 compliance is balance sheet volatility. As an occurrence of risk-aware accounting, IFRS 17 requires the value of insurance services to be market-adjusted. This adjustment is based on a firm’s projection of future cash flow, informed by calculated financial risk. Moreover, although this will not be the first time firms are incorporating non-financial risk into valuations, it is the first time it has to be explicit.
Market volatility will be reflected in the balance sheet, as liabilities and assets are subject to interest rate fluctuation and other financial risks. The way financial risk is incorporated into the value of a contract can also contribute to balance sheet volatility. The way it is incorporated is dictated by the measurement model used to value it, which depends on the eligibility of the contract.
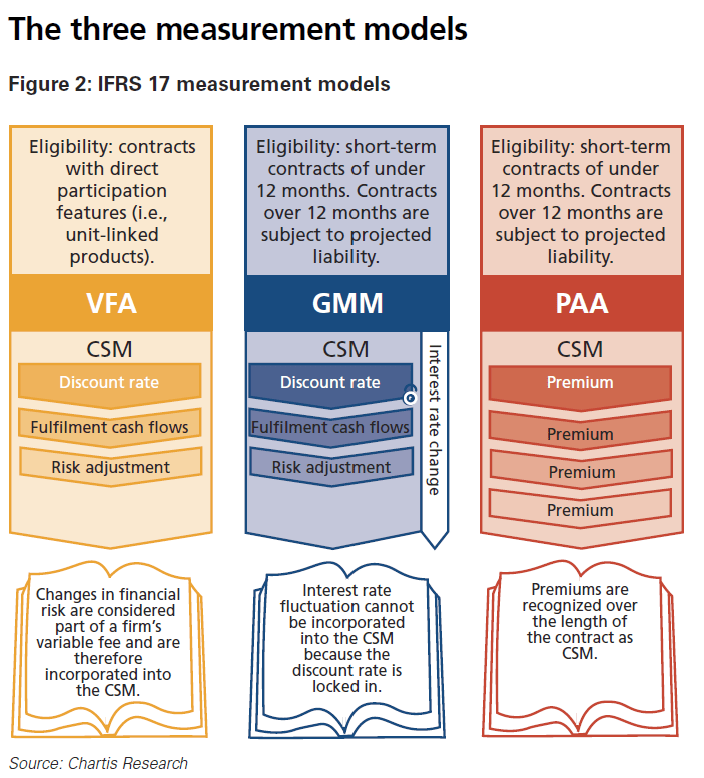
There are three measurement models, the PAA, the GMM and the variable fee approach (VFA). All three are considered in the next section.
The three measurement models
Features of the three measurement models (see Figure 2) can have significant effects on how profit – represented by the CSM – is presented and ultimately disclosed.
To illustrate the choices around accounting policy that insurance firms will need to consider and make, we provide two specific examples, for the PAA and the GMM.
Accounting policy choices: the PAA
When applying the PAA to shorter contracts – generally those of fewer than 12 months – firms have several choices to make about accounting policy. One is whether to defer acquisition costs. Unlike previous reporting regimes, under IFRS17’s PAA indirect costs cannot be deferred as acquisition costs. Firms can either expense these costs upfront or defer them and amortize the cost over the length of the contract. Expensing acquisition costs as they are incurred may affect whether a group of contracts is characterized as onerous at inception. Deferring acquisition costs reduces the liability for the remaining coverage; however, it may also increase the loss recognized in the income statement for onerous contracts.
Accounting policy choices: the GMM
Under IFRS 17, revenue is the sum of
- the release of CSM,
- changes in the risk adjustment,
- and expected net cash outflows, excluding any investment components.
Excluding any investment component from revenue recognition will have significant impacts on contracts being sold by life insurers.
Contracts without direct participation features measured under the GMM use a locked-in discount rate – whether this is calculated ‘top down’ or ‘bottom up’ is at the discretion of the firm. Changes to the CSM have to be made using the discount rate set at the initial recognition of the contract. Changes in financial variables that differ from the locked-in discount rate cannot be integrated into the CSM, so appear as insurance service value.
A firm must account for the changes directly in the comprehensive income statement, and this can also contribute to balance sheet volatility.
As part of their accounting policy firms have a choice about how to recognize changes in discount rates and other changes to financial risk assumptions – between other comprehensive income (OCI) and profit and loss (P&L). Recognizing fluctuations in discount rates and financial risk in the OCI reduces some volatility in P&L. Firms also recognize the fair value of assets
in the OCI under IFRS 9.
- The technology perspective
Data integrity and control
At the center of IFRS 17 compliance and reporting is the management of a wide spectrum of data – firms will have to gather and generate data from historic, current and forward-looking perspectives.
Creating IFRS 17 reports will be a non-linear process, and data will be incorporated as it becomes available from multiple sources. For many firms, contending with this level of data granularity and volume will be a big leap from other reporting requirements. The maturity of an insurer’s data infrastructure is partly defined by the regulatory and reporting context it was built in, and in which it operates – entities across the board will have to upgrade their data management technology.
In regions such as Southeast Asia and the Middle East, however, data management on the scale of IFRS 17 is unprecedented. Entities operating in these regions in particular will have to expend considerable effort to upgrade their infrastructure. Manual spreadsheets and complex legacy systems will have to be replaced with data management technology across the compliance value chain.
According to a 2018 survey by Deloitte, 87% of insurers believed that their systems technology required upgrades to capture the new data they have to handle and perform the calculations they require for compliance. Capturing data inputs was cited as the biggest technology challenge.
Tracking and linking the data lifecycle
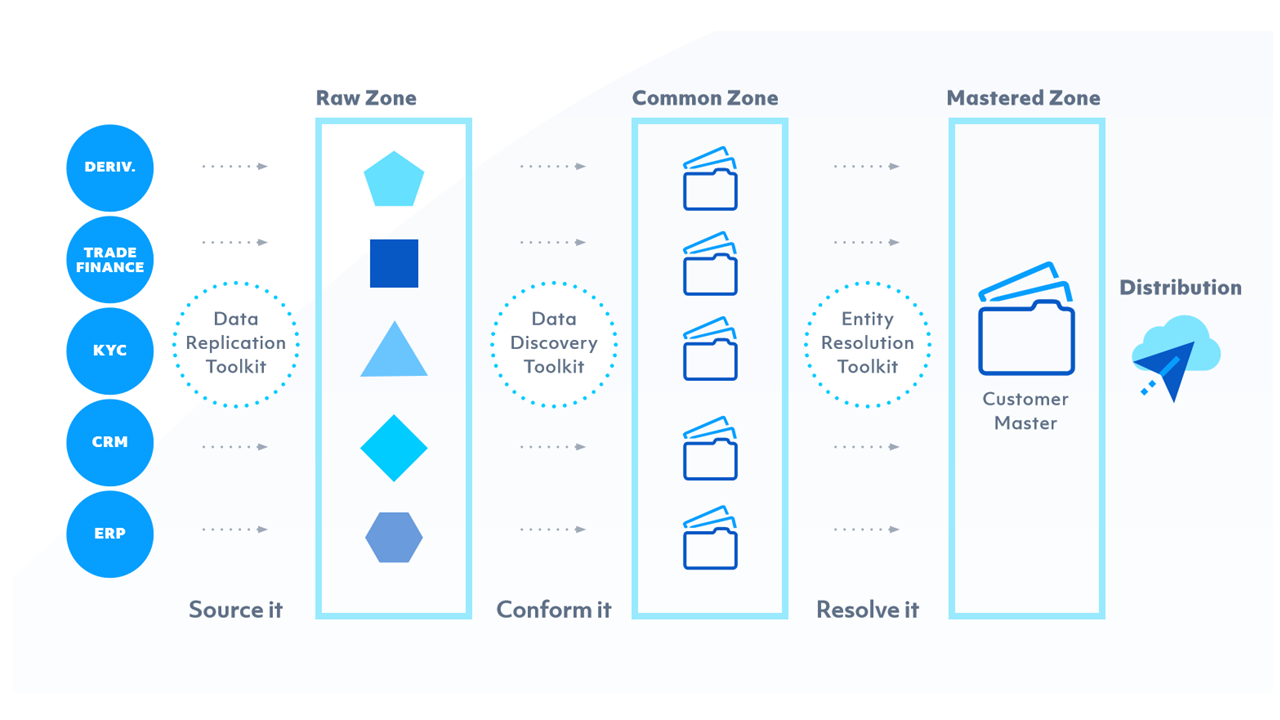
Compliance with IFRS 17 demands data governance across the entire insurance contract valuation process. The data journey starts at the data source and travels through aggregation and modeling processes all the way to the disclosure stage (see Figure 3).

In this section we focus on the specific areas of data lineage, data tracking and the auditing processes that run along the entire data compliance value chain. For contracts longer than 12 months, the valuation process will be iterative, as data is transformed multiple times by different users. Having a single version of reporting data makes it easier to collaborate, track and manage the iterative process of adapting to IFRS 17. Cloud platforms help to address this challenge, providing an effective means of storing and managing the large volumes of reporting data generated by IFRS 17. The cloud allows highly scalable, flexible technology to be delivered on demand, enabling simultaneous access to the same data for internal teams and external advisors.
It is essential that amendments are tracked and stored as data falls through different hands and passes through different IFRS 17 ‘compliance stages’. Data lineage processes can systematically track users’ interactions with data and improve the ‘auditability’ of the compliance process and users’ ‘ownership’ of activity.
Data linking is another method of managing IFRS 17 reporting data. Data linking contributes to data integrity while enabling multiple users to make changes to data. It enables the creation of relationships across values while maintaining the integrity of the source value, so changing the source value creates corresponding changes across all linked values. Data linking also enables the automated movement of data from spreadsheets to financial reports, updating data as it is changed and tracking users’ changes to it.
Disclosing the data
Highlighting how IFRS 17 is more than just a compliance exercise, it will have a fundamental impact on how insurance companies report their data internally, to regulators, and to financial markets. For the final stage of compliance, firms will need to adopt a new format for the balance sheet, P&L statement and cash flow statements.
In addition to the standard preparation of financial statements, IFRS 17 will require a number of disclosures, including the explanation of recognized amounts, significant judgements made in applying IFRS 17, and the nature and extent of risks arising from insurance contracts. As part of their conversion to IFRS 17, firms will need to assess how data will have to be managed on a variety of levels, including
- transactions,
- financial statements,
- regulatory disclosures,
- internal key performance indicators
- and communications to financial markets.
Communication with capital markets will be more complex, because of changes that will have to be made in several areas:
- The presentation of financial results.
- Explanations of how calculations were made, and around the increased complexity of the calculations.
- Footnotes to explain how data is being reported in ‘before’ and ‘after’ conversion scenarios.
During their transition, organizations will have to report and explain to the investor community which changes were the result of business performance and which were the result of a change in accounting basis. The new reporting basis will also impact how data will be reported internally, as well as overall effects on performance management. The current set of key metrics used for performance purposes, including volume, revenue, risk and profitability, will have to be adjusted for the new methodology and accounting basis. This could affect how data will be reported on and reconciled for current regulatory reporting requirements including Solvency II, local solvency standards, and broader statutory and tax reporting.
IFRS 17 will drive significant changes in the current reporting environment. To address this challenge, firms must plan how they will manage both the pre-conversion and post-conversion data sets, the preparation of pre-, post-, and comparative financial statements, and the process of capturing and disclosing all of the narrative that will support and explain these financial results.
In addition, in managing the complexity of the numbers and the narrative before, during and after the conversion, reporting systems will also need to scale to meet the requirements of regulatory reporting – including disclosure in eXtensible Business
Reporting Language (XBRL) in some jurisdictions. XBRL is a global reporting markup language that enables the encoding of documents in a human and machine-legible format for business reporting (The IASB publishes its IFRS Taxonomy files in
XBRL).
But XBRL tagging can be a complex, time-consuming and repetitive process, and firms should consider using available technology partners to support the tagging and mapping demands of document drafting.