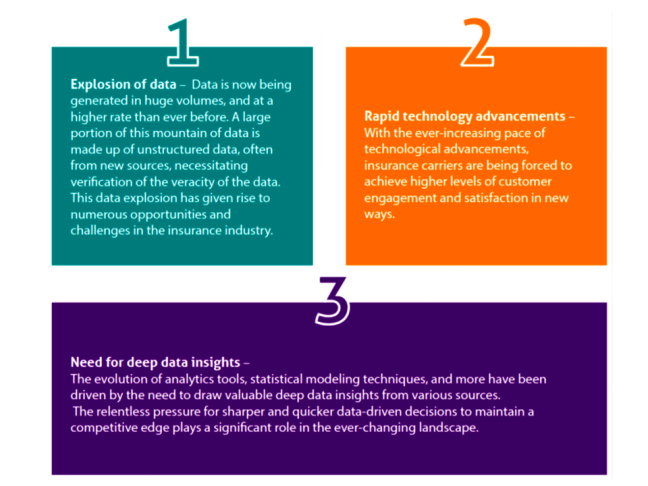
When it comes to being data-driven, organizations run the gamut with maturity levels. Most believe that data and analytics provide insights. But only one-third of respondents to a TDWI survey said they were truly data-driven, meaning they analyze data to drive decisions and actions.
Successful data-driven businesses foster a collaborative, goal-oriented culture. Leaders believe in data and are governance-oriented. The technology side of the business ensures sound data quality and puts analytics into operation. The data management strategy spans the full analytics life cycle. Data is accessible and usable by multiple people – data engineers and data scientists, business analysts and less-technical business users.
TDWI analyst Fern Halper conducted research of analytics and data professionals across industries and identified the following five best practices for becoming a data-driven organization.
1. Build relationships to support collaboration
If IT and business teams don’t collaborate, the organization can’t operate in a data-driven way – so eliminating barriers between groups is crucial. Achieving this can improve market performance and innovation; but collaboration is challenging. Business decision makers often don’t think IT understands the importance of fast results, and conversely, IT doesn’t think the business understands data management priorities. Office politics come into play.
But having clearly defined roles and responsibilities with shared goals across departments encourages teamwork. These roles should include: IT/architecture, business and others who manage various tasks on the business and IT sides (from business sponsors to DevOps).
2. Make data accessible and trustworthy
Making data accessible – and ensuring its quality – are key to breaking down barriers and becoming data-driven. Whether it’s a data engineer assembling and transforming data for analysis or a data scientist building a model, everyone benefits from trustworthy data that’s unified and built around a common vocabulary.
As organizations analyze new forms of data – text, sensor, image and streaming – they’ll need to do so across multiple platforms like data warehouses, Hadoop, streaming platforms and data lakes. Such systems may reside on-site or in the cloud. TDWI recommends several best practices to help:
- Establish a data integration and pipeline environment with tools that provide federated access and join data across sources. It helps to have point-and-click interfaces for building workflows, and tools that support ETL, ELT and advanced specifications like conditional logic or parallel jobs.
- Manage, reuse and govern metadata – that is, the data about your data. This includes size, author, database column structure, security and more.
- Provide reusable data quality tools with built-in analytics capabilities that can profile data for accuracy, completeness and ambiguity.
3. Provide tools to help the business work with data
From marketing and finance to operations and HR, business teams need self-service tools to speed and simplify data preparation and analytics tasks. Such tools may include built-in, advanced techniques like machine learning, and many work across the analytics life cycle – from data collection and profiling to monitoring analytical models in production.
These “smart” tools feature three capabilities:
- Automation helps during model building and model management processes. Data preparation tools often use machine learning and natural language processing to understand semantics and accelerate data matching.
- Reusability pulls from what has already been created for data management and analytics. For example, a source-to-target data pipeline workflow can be saved and embedded into an analytics workflow to create a predictive model.
- Explainability helps business users understand the output when, for example, they’ve built a predictive model using an automated tool. Tools that explain what they’ve done are ideal for a data-driven company.
4. Consider a cohesive platform that supports collaboration and analytics
As organizations mature analytically, it’s important for their platform to support multiple roles in a common interface with a unified data infrastructure. This strengthens collaboration and makes it easier for people to do their jobs.
For example, a business analyst can use a discussion space to collaborate with a data scientist while building a predictive model, and during testing. The data scientist can use a notebook environment to test and validate the model as it’s versioned and metadata is captured. The data scientist can then notify the DevOps team when the model is ready for production – and they can use the platform’s tools to continually monitor the model.
5. Use modern governance technologies and practices
Governance – that is, rules and policies that prescribe how organizations protect and manage their data and analytics – is critical in learning to trust data and become data-driven. But TDWI research indicates that one-third of organizations don’t govern their data at all. Instead, many focus on security and privacy rules. Their research also indicates that fewer than 20 percent of organizations do any type of analytics governance, which includes vetting and monitoring models in production.
Decisions based on poor data – or models that have degraded – can have a negative effect on the business. As more people across an organization access data and build models, and as new types of data and technologies emerge (big data, cloud, stream mining), data governance practices need to evolve. TDWI recommends three features of governance software that can strengthen your data and analytics governance:
- Data catalogs, glossaries and dictionaries. These tools often include sophisticated tagging and automated procedures for building and keeping catalogs up to date – as well as discovering metadata from existing data sets.
- Data lineage. Data lineage combined with metadata helps organizations understand where data originated and track how it was changed and transformed.
- Model management. Ongoing model tracking is crucial for analytics governance. Many tools automate model monitoring, schedule updates to keep models current and send alerts when a model is degrading.
In the future, organizations may move beyond traditional governance council models to new approaches like agile governance, embedded governance or crowdsourced governance.
But involving both IT and business stakeholders in the decision-making process – including data owners, data stewards and others – will always be key to robust governance at data-driven organizations.
There’s no single blueprint for beginning a data analytics project – never mind ensuring a successful one.
However, the following questions help individuals and organizations frame their data analytics projects in instructive ways. Put differently, think of these questions as more of a guide than a comprehensive how-to list.
1. Is this your organization’s first attempt at a data analytics project?
When it comes to data analytics projects, culture matters. Consider Netflix, Google and Amazon. All things being equal, organizations like these have successfully completed data analytics projects. Even better, they have built analytics into their cultures and become data-driven businesses.
As a result, they will do better than neophytes. Fortunately, first-timers are not destined for failure. They should just temper their expectations.
2. What business problem do you think you’re trying to solve?
This might seem obvious, but plenty of folks fail to ask it before jumping in. Note here how I qualified the first question with “do you think.” Sometimes the root cause of a problem isn’t what we believe it to be; in other words, it’s often not what we at first think.
In any case, you don’t need to solve the entire problem all at once by trying to boil the ocean. In fact, you shouldn’t take this approach. Project methodologies (like agile) allow organizations to take an iterative approach and embrace the power of small batches.
3. What types and sources of data are available to you?
Most if not all organizations store vast amounts of enterprise data. Looking at internal databases and data sources makes sense. Don’t make the mistake of believing, though, that the discussion ends there.
External data sources in the form of open data sets (such as data.gov) continue to proliferate. There are easy methods for retrieving data from the web and getting it back in a usable format – scraping, for example. This tactic can work well in academic environments, but scraping could be a sign of data immaturity for businesses. It’s always best to get your hands on the original data source when possible.
Caveat: Just because the organization stores it doesn’t mean you’ll be able to easily access it. Pernicious internal politics stifle many an analytics endeavor.
4. What types and sources of data are you allowed to use?
With all the hubbub over privacy and security these days, foolish is the soul who fails to ask this question. As some retail executives have learned in recent years, a company can abide by the law completely and still make people feel decidedly icky about the privacy of their purchases. Or, consider a health care organization – it may not technically violate the Health Insurance Portability and Accountability Act of 1996 (HIPAA), yet it could still raise privacy concerns.
Another example is the GDPR. Adhering to this regulation means that organizations won’t necessarily be able to use personal data they previously could use – at least not in the same way.
5. What is the quality of your organization’s data?
Common mistakes here include assuming your data is complete, accurate and unique (read: nonduplicate). During my consulting career, I could count on one hand the number of times a client handed me a “perfect” data set. While it’s important to cleanse your data, you don’t need pristine data just to get started. As Voltaire said, “Perfect is the enemy of good.”
6. What tools are available to extract, clean, analyze and present the data?
This isn’t the 1990s, so please don’t tell me that your analytic efforts are limited to spreadsheets. Sure, Microsoft Excel works with structured data – if the data set isn’t all that big. Make no mistake, though: Everyone’s favorite spreadsheet program suffers from plenty of limitations, in areas like:
- Handling semistructured and unstructured data.
- Tracking changes/version control.
- Dealing with size restrictions.
- Ensuring governance.
- Providing security.
For now, suffice it to say that if you’re trying to analyze large, complex data sets, there are many tools well worth exploring. The same holds true for visualization. Never before have we seen such an array of powerful, affordable and user-friendly tools designed to present data in interesting ways.
Caveat 1: While software vendors often ape each other’s features, don’t assume that each application can do everything that the others can.
Caveat 2: With open source software, remember that “free” software could be compared to a “free” puppy. To be direct: Even with open source software, expect to spend some time and effort on training and education.
7. Do your employees possess the right skills to work on the data analytics project?
The database administrator may well be a whiz at SQL. That doesn’t mean, though, that she can easily analyze gigabytes of unstructured data. Many of my students need to learn new programs over the course of the semester, and the same holds true for employees. In fact, organizations often find that they need to:
- Provide training for existing employees.
- Hire new employees.
- Contract consultants.
- Post the project on sites such as Kaggle.
- All of the above.
Don’t assume that your employees can pick up new applications and frameworks 15 minutes at a time every other week. They can’t.
8. What will be done with the results of your analysis?
A company routinely spent millions of dollars recruiting MBAs at Ivy League schools only to see them leave within two years. Rutgers MBAs, for their part, stayed much longer and performed much better.
Despite my findings, the company continued to press on. It refused to stop going to Harvard, Cornell, etc. because of vanity. In his own words, the head of recruiting just “liked” going to these schools, data be damned.
Food for thought: What will an individual, group, department or organization do with keen new insights from your data analytics projects? Will the result be real action? Or will a report just sit in someone’s inbox?
9. What types of resistance can you expect?
You might think that people always and willingly embrace the results of data-oriented analysis. And you’d be spectacularly wrong.
Case in point: Major League Baseball (MLB) umpires get close ball and strike calls wrong more often than you’d think. Why wouldn’t they want to improve their performance when presented with objective data? It turns out that many don’t. In some cases, human nature makes people want to reject data and analytics that contrast with their world views. Years ago, before the subscription model became wildly popular, some Blockbuster executives didn’t want to believe that more convenient ways to watch movies existed.
Caveat: Ignore the power of internal resistance at your own peril.
10. What are the costs of inaction?
Sure, this is a high-level query and the answers depend on myriad factors.
For instance, a pharma company with years of patent protection will respond differently than a startup with a novel idea and competitors nipping at its heels. Interesting subquestions here include:
- Do the data analytics projects merely confirm what we already know?
- Do the numbers show anything conclusive?
- Could we be capturing false positives and false negatives?
Think about these questions before undertaking data analytics projects Don’t take the queries above as gospel. By and large, though, experience proves that asking these questions frames the problem well and sets the organization up for success – or at least minimizes the chance of a disaster.
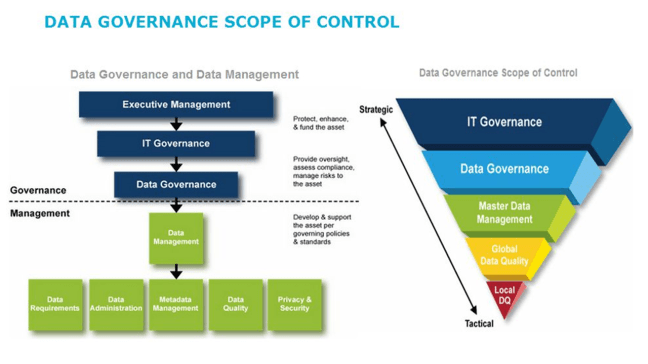
Most organizations understand the importance of data governance in concept. But they may not realize all the multifaceted, positive impacts of applying good governance practices to data across the organization. For example, ensuring that your sales and marketing analytics relies on measurably trustworthy customer data can lead to increased revenue and shorter sales cycles. And having a solid governance program to ensure your enterprise data meets regulatory requirements could help you avoid penalties.
Companies that start data governance programs are motivated by a variety of factors, internal and external. Regardless of the reasons, two common themes underlie most data governance activities: the desire for high-quality customer information, and the need to adhere to requirements for protecting and securing that data.
What’s the best way to ensure you have accurate customer data that meets stringent requirements for privacy and security?
For obvious reasons, companies exert significant effort using tools and third-party data sets to enforce the consistency and accuracy of customer data. But there will always be situations in which the managed data set cannot be adequately synchronized and made consistent with “real-world” data. Even strictly defined and enforced internal data policies can’t prevent inaccuracies from creeping into the environment.
Why you should move beyond a conventional approach to data governance?
When it comes to customer data, the most accurate sources for validation are the customers themselves! In essence, every customer owns his or her information, and is the most reliable authority for ensuring its quality, consistency and currency. So why not develop policies and methods that empower the actual owners to be accountable for their data?
Doing this means extending the concept of data governance to the customers and defining data policies that engage them to take an active role in overseeing their own data quality. The starting point for this process fits within the data governance framework – define the policies for customer data validation.
A good template for formulating those policies can be adapted from existing regulations regarding data protection. This approach will assure customers that your organization is serious about protecting their data’s security and integrity, and it will encourage them to actively participate in that effort.
Examples of customer data engagement policies
- Data protection defines the levels of protection the organization will use to protect the customer’s data, as well as what responsibilities the organization will assume in the event of a breach. The protection will be enforced in relation to the customer’s selected preferences (which presumes that customers have reviewed and approved their profiles).
- Data access control and security define the protocols used to control access to customer data and the criteria for authenticating users and authorizing them for particular uses.
- Data use describes the ways the organization will use customer data.
- Customer opt-in describes the customers’ options for setting up the ways the organization can use their data.
- Customer data review asserts that customers have the right to review their data profiles and to verify the integrity, consistency and currency of their data. The policy also specifies the time frame in which customers are expected to do this.
- Customer data update describes how customers can alert the organization to changes in their data profiles. It allows customers to ensure their data’s validity, integrity, consistency and currency.
- Right-to-use defines the organization’s right to use the data as described in the data use policy (and based on the customer’s selected profile options). This policy may also set a time frame associated with the right-to-use based on the elapsed time since the customer’s last date of profile verification.
The goal of such policies is to establish an agreement between the customer and the organization that basically says the organization will protect the customer’s data and only use it in ways the customer has authorized – in return for the customer ensuring the data’s accuracy and specifying preferences for its use. This model empowers customers to take ownership of their data profile and assume responsibility for its quality.
Clearly articulating each party’s responsibilities for data stewardship benefits both the organization and the customer by ensuring that customer data is high-quality and properly maintained. Better yet, recognize that the value goes beyond improved revenues or better compliance.
Empowering customers to take control and ownership of their data just might be enough to motivate self-validation.