Introduction
Businesses that use legacy data sources such as mainframe have invested heavily in building a reliable data platform. At the same time, these enterprises want to move data into the cloud for the latest in analytics, data science and machine learning.
The Importance of Legacy Data
Mainframe is still the processing backbone for many organizations, constantly generating important business data.
It’s crucial to consider the following:
MAINFRAME IS THE ENTERPRISE TRANSACTION ENVIRONMENT
In 2019, there was a 55% increase in transaction volume on mainframe environments. Studies estimate that 2.5 billion transactions are run per day, per legacy system across the world.
LEGACY IS THE FUEL BEHIND CUSTOMER EXPERIENCES
Within industries such as financial services and insurance, most customer information lives on legacy systems. Over 70% of enterprises say their customer-facing applications are completely or very reliant on mainframe processing.
BUSINESS-CRITICAL APPLICATIONS RUN ON LEGACY SYSTEMS
Mainframe often holds business-critical information and applications — from credit card transactions to claims processing. For over half of enterprises with a mainframe, they run more than half of their business-critical applications on the platform.
However, they also present a limitation for an organization in its analytics and data science journey. While moving everything to the cloud may not be the answer, identifying ways in which you can start a legacy modernization process is crucial to the next generation of data and AI initiatives.
The Cost of Legacy Data
Across the enterprise, legacy systems such as mainframe serve as a critical piece of infrastructure that is ripe with opportunity for integration with modern analytics platforms. If a modern analytics platform is only as good as the data fed into it, that means enterprises must include all data sources for success. However, many complexities can occur when organizations look to build the data integration pipelines between their modern analytics platform and legacy sources. As a result, the plans made to connect these two areas are often easier said than done.
DATA SILOS HINDER INNOVATION
Over 60% of IT professionals with legacy and modern technology in house are finding that data silos are negatively affecting their business. As data volumes increase, IT can no longer rely on current data integration approaches to solve their silo challenges.
CLOUDY BUSINESS INSIGHTS
Business demands that more decisions are driven by data. Still, few IT professionals who work with legacy systems feel they are successful in delivering data insights that reside outside their immediate department. Data-driven insights will be the key to competitive success. The inability to provide insights puts a business at risk.
SKILLS GAP WIDENS
While it may be difficult to find skills for the latest technology, it’s becoming even harder to find skills for legacy platforms. Enterprises have only replaced 37% of the mainframe workforce lost over the past five years. As a result, the knowledge needed to integrate mainframe data into analytics platforms is disappearing. While the drive for building a modern analytics platform is more powerful than ever, taking this initiative and improving data integration practices that encompass all enterprise data has never been more challenging.
The success of building a modern analytics platform hinges on understanding the common challenges of integrating legacy data sources and choosing the right technologies that can scale with the changing needs of your organization.
Challenges Specific to Extracting Mainframe Data
With so much valuable data on mainframe, the most logical thing to do would be to connect these legacy data sources to a modern data platform. However, many complexities can occur when organizations begin to build integration pipelines to legacy sources. As a result, the plans made to connect these two areas are often easier said than done. Shared challenges of extracting mainframe data for integration with modern analytics platforms include the following:
DATA STRUCTURE
It’s common for legacy data not to be readily compatible with downstream analytics platforms, open-source frameworks and data formats. The varied structures of legacy data sources differ from relational data. Legacy data sources have traits such as
- hierarchical tables,
- embedded headers,
- and trailer and complex data structures (e.g., nested, repeated or redefined elements).
With the incorrect COBOL redefines and logic set up at the start of a data integration workflow, legacy data structures risk slowing down processing speeds to the point of business disruption and can lead to incorrect data for downstream consumption.
METADATA
COBOL copybooks can be a massive hurdle to overcome for integrating mainframe data. COBOL copybooks are the metadata blocks that define the physical layout of data but are stored separately from that data. As a result, they can be quite complicated, containing not just formatting information, but also logic in the form, for example, of nested Occurs Depending On clauses. For many mainframe files, hundreds of copybooks may map to a single file. Feeding mainframe data directly into an analytics platform can result in significant data confusion.
DATA MAPPING
Unlike an RDBMS, which needs data to be entered into a table or column, nothing enforces a set data structure on the mainframe. COBOL copybooks are incredibly flexible so that they
- can group multiple pieces into one,
- or subdivide a field into various fields,
- or ignore whole sections of a record.
As a result, data mapping issues will arise. The copybooks reflect the needs of the program, not the needs of a data-driven view.
DIFFERENT STORAGE FORMATS
Often numeric values stored one way on a mainframe are stored differently when the data is moving to the cloud. Additionally, mainframes use a whole different encoding scheme (EBCDIC vs. ASCII) — it’s an 8-bit structure vs. a 7-bit structure. As a result, multiple numeric encoding schemes allow for the ability to “pack” numbers into less storage (e.g., packed decimal) space. In addition to complex storage formats, there are techniques to use each individual bit to store data.
Whether it’s a lack of internal knowledge on how to handle legacy data or a rigid data framework, ignoring legacy data when building a modern data analytics platform means missing valuable information that can enhance any analytics project.
Pain Points of Building a Modern Analytics Platform
Tackling the challenges of mainframe data integration is no simple task. Besides determining the best approach for integrating these legacy data sources, IT departments are also dealing with the everyday challenges of running a department. Regardless of the size of an organization, there are daily struggles everyone faces, from siloed data to lack of IT skills.
ENVIRONMENT COMPLEXITY
Many organizations have adopted hybrid and multi-cloud strategies to
- manage data proliferation,
- gain flexibility,
- reduce costs
- and increase capacities.
Cloud storage and the lakehouse architecture offer new ways to manage and store data. However, organizations still need to maintain and integrate their mainframes and other on-premises systems — resulting in a challenging integration strategy that must encompass a variety of environments.
SILOED DATA
The increase in data silos adds further complexity to growing data volumes. Data silo creation happens as a direct result of increasing data sources. Research has shown that data silos have directly inhibited the success of analytics and machine learning projects.
PERFORMANCE
Processing the requirements of growing data volumes can cause a slowdown in a data stream. Loading hundreds, or even thousands, of database tables into a big data platform — combined with an inefficient use of system resources — can create a data bottleneck that hampers the performance of data integration pipelines.
DATA QUALITY
Industry studies have shown that up to 90% of a data scientist’s time is getting data to the right condition for use in analytics. In other words, 90% of the time, data feeding analytics cannot be trusted. Data quality processes that include
- mapping,
- matching,
- linking,
- merging,
- deduplication
- and actionable data
are critical to providing frameworks with trusted data.
DATA TYPES AND FORMATS
Valuable data for analytics comes from a range of sources across the organization from CRM, ERPs, mainframes and online transaction processing systems. However, as organizations rely on more systems, the data types and formats continue to grow.
IT now has the challenge of making big data, NoSQL and unstructured data all readable for downstream analytics solutions.
SKILLS GAP AND RESOURCES
The need for workers who understand how to build data integration frameworks for mainframe, cloud, and cluster data sources is increasing, but the market cannot keep up. Studies have shown that unfilled data engineer jobs and data scientist jobs have increased 12x in the past year alone. As a result, IT needs to figure out how to integrate data for analytics with the skills they have internally.
What Your Cloud Data Platform Needs
A new data management paradigm has emerged that combines the best elements of data lakes and data warehouses, enabling
- analytics,
- data science
- and machine learning
on all your business data: lakehouse.
Lakehouses are enabled by a new system design: implementing similar data structures and data management features to those in a data warehouse, directly on the kind of low-cost storage used for data lakes. They are what you would get if you had to redesign data warehouses in the modern world, now that cheap and highly reliable storage (in the form of object stores) are available.
This new paradigm is the vision for data management that provides the best architecture for modern analytics and AI. It will help organizations capture data from hundreds of sources, including legacy systems, and make that data available and ready for analytics, data science and machine learning.
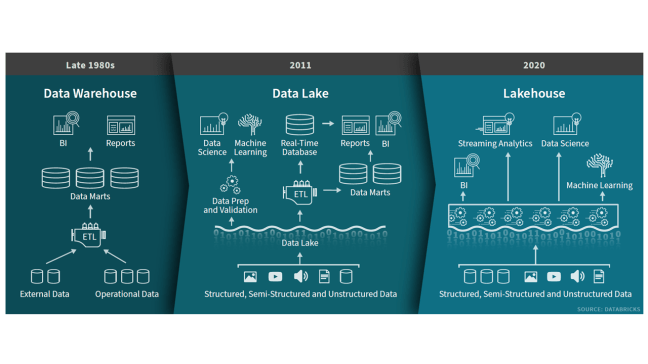
A lakehouse has the following key features:
- Open storage formats, such as Parquet, avoid lock-in and provide accessibility to the widest variety of analytics tools and applications
- Decoupled storage and compute provides the ability to scale to many concurrent users by adding compute clusters that all access the same storage cluster
- Transaction support handles failure scenarios and provides consistency when multiple jobs concurrently read and write data
- Schema management enforces the expected schema when needed and handles evolving schemas as they change over time
- Business intelligence tools directly access the lakehouse to query data, enabling access to the latest data without the cost and complexity of replicating data across a data lake and a data warehouse
- Data science and machine learning tools used for advanced analytics rely on the same data repository
- First-class support for all data types across structured, semi-structured and unstructured, plus batch and streaming data
Click here to access Databricks’ and Precisely’s White Paper