
Data travels faster than ever, anywhere and all the time. Yet as fast as it moves, it has barely been able to keep up with the expanding agendas of financial supervisors. You might not know it to look at them, but the authorities in Basel, Washington, London, Singapore and other financial and political centers are pretty swift themselves when it comes to devising new requirements for compiling and reporting data. They seem to want nothing less than a renaissance in the way institutions organize and manage their finance, risk and regulatory reporting activities.
The institutions themselves might want the same thing. Some of the business strategies and tactics that made good money for banks before the global financial crisis have become unsustainable and cut into their profitability. More stringent regulator frameworks imposed since the crisis require the implementation of complex, data-intensive stress testing procedures and forecasting models that call for unceasing monitoring and updating. The days of static reports capturing a moment in a firm’s life are gone. One of the most challenging data management burdens is rooted in duplication. The evolution of regulations has left banks with various bespoke databases across five core functions:
- credit,
- treasury,
- profitability analytics,
- financial reporting
- and regulatory reporting,
with the same data inevitably appearing and processed in multiple places. This hodgepodge of bespoke marts simultaneously leads to both the duplication of data and processes, and the risk of inconsistencies – which tend to rear their head at inopportune moments (i.e. when consistent data needs to be presented to regulators). For example,
- credit extracts core loan, customer and credit data;
- treasury pulls core cash flow data from all instruments;
- profitability departments pull the same instrument data as credit and treasury and add ledger information for allocations;
- financial reporting pulls ledgers and some subledgers for reporting;
- and regulatory reporting pulls the same data yet again to submit reports to regulators per prescribed templates.
The ever-growing list of considerations has compelled firms to revise, continually and on the fly, not just how they manage their data but how they manage their people and basic organizational structures. An effort to integrate activities and foster transparency – in particular through greater cooperation among risk and finance – has emerged across financial services. This often has been in response to demands from regulators, but some of the more enlightened leaders in the industry see it as the most sensible way to comply with supervisory mandates and respond to commercial exigencies, as well. Their ability to do that has been constrained by the variety, frequency and sheer quantity of information sought by regulators, boards and senior executives. But that is beginning to change as a result of new technological capabilities and, at least as important, new management strategies. This is where the convergence of Finance, Risk and Regulatory Reporting (FRR) comes in. The idea behind the FRR theme is that sound regulatory compliance and sound business analytics are manifestations of the same set of processes. Satisfying the demands of supervisory authorities and maximizing profitability and competitiveness in the marketplace involve similar types of analysis, modeling and forecasting. Each is best achieved, therefore, through a comprehensive, collaborative organizational structure that places the key functions of finance, risk and regulatory reporting at its heart.
The glue that binds this entity together and enables it to function as efficiently and cost effectively as possible – financially and in the demands placed on staff – is a similarly comprehensive and unified FRR data management. The right architecture will permit data to be drawn upon from all relevant sources across an organization, including disparate legacy hardware and software accumulated over the years in silos erected for different activities ad geographies. Such an approach will reconcile and integrate this data and present it in a common, consistent, transparent fashion, permitting it to be deployed in the most efficient way within each department and for every analytical and reporting need, internal and external.
The immense demands for data, and for a solution to manage it effectively, have served as a catalyst for a revolutionary development in data management: Regulatory Technology, or RegTech. The definition is somewhat flexible and tends to vary with the motivations of whoever is doing the defining, but RegTech basically is the application of cutting-edge hardware, software, design techniques and services to the idiosyncratic challenges related to financial reporting and compliance. The myriad advances that fall under the RegTech rubric, such as centralized FRR or RegTech data management and analysis, data mapping and data visualization, are helping financial institutions to get out in front of the stringent reporting requirements at last and accomplish their efforts to integrate finance, risk and regulatory reporting duties more fully, easily and creatively.
A note of caution though: While new technologies and new thinking about how to employ them will present opportunities to eliminate weaknesses that are likely to have crept into the current architecture, ferreting out those shortcomings may be tricky because some of them will be so ingrained and pervasive as to be barely recognizable. But it will have to be done to make the most of the systems intended to improve or replace existing ones.
Just what a solution should encompass to enable firms to meet their data management objectives depends on the
- specifics of its business, including its size and product lines,
- the jurisdictions in which it operates,
- its IT budget
- and the tech it has in place already.
But it should accomplish three main goals:
- Improving data lineage by establishing a trail for each piece of information at any stage of processing
- Providing a user-friendly view of the different processing step to foster transparency
- Working together seamlessly with legacy systems so that implementation takes less time and money and imposes less of a burden on employees.
The two great trends in financial supervision – the rapid rise in data management and reporting requirements, and the demands for greater organizational integration – can be attributed to a single culprit: the lingering silo structure. Fragmentation continues to be supported by such factors as a failure to integrate the systems of component businesses after a merger and the tendency of some firms to find it more sensible, even if it may be more costly and less efficient in the long run, to install new hardware and software whenever a new set of rules comes along. That makes regulators – the people pressing institutions to break down silos in the first place – inadvertently responsible for erecting new barriers.
This bunker mentality – an entrenched system of entrenchment – made it impossible to recognize the massive buildup of credit difficulties that resulted in the global crisis. It took a series of interrelated events to spark the wave of losses and insolvencies that all but brought down the financial system. Each of them might have appeared benign or perhaps ominous but containable when taken individually, and so the occupants of each silo, who could only see a limited number of the warning signs, were oblivious to the extent of the danger. More than a decade has passed since the crisis began, and many new supervisory regimens have been introduced in its aftermath. Yet bankers, regulators and lawmakers still feel the need, with justification, to press institutions to implement greater organizational integration to try to forestall the next meltdown. That shows how deeply embedded the silo system is in the industry.
Data requirements for the development that, knock on wood, will limit the damage from the next crisis – determining what will happen, rather than identifying and explaining what has already happened – are enormous. The same goes for running an institution in a more integrated way. It’s not just more data that’s needed, but more kinds of data and more reliable data. A holistic, coordinated organizational structure, moreover, demands that data be analyzed at a higher level to reconcile the massive quantities and types of information produced within each department. And institutions must do more than compile and sort through all that data. They have to report it to authorities – often quarterly or monthly, sometimes daily and always when something is flagged that could become a problem. Indeed, some data needs to be reported in real time. That is a nearly impossible task for a firm still dominated by silos and highlights the need for genuinely new design and implementation methods that facilitate the seamless integration of finance, risk and regulatory reporting functions. Among the more data-intensive regulatory frameworks introduced or enhanced in recent years are:
- IFRS 9 Financial Instruments and Current Expected Credit Loss. The respective protocols of the International Accounting Standards Board and Financial Accounting Standards Board may provide the best examples of the forwardthinking approach – and rigorous reporting, data management and compliance procedures – being demanded. The standards call for firms to forecast credit impairments to assets on their books in near real time. The incurred-loss model being replaced merely had banks present bad news after the fact. The number of variables required to make useful forecasts, plus the need for perpetually running estimates that hardly allow a chance to take a breath, make the standards some of the most data-heavy exercises of all.
- Stress tests here, there and everywhere. Whether for the Federal Reserve’s Comprehensive Capital Analysis and Review (CCAR) for banks operating in the United States, the Firm Data Submission Framework (FDSF) in Britain or Asset Quality Reviews, the version conducted by the European Banking Authority (EBA) for institutions in the euro zone, stress testing has become more frequent and more free-form, too, with firms encouraged to create stress scenarios they believe fit their risk profiles and the characteristics of their markets. Indeed, the EBA is implementing a policy calling on banks to conduct stress tests as an ongoing risk management procedure and not merely an assessment of conditions at certain discrete moments.
- Dodd-Frank Wall Street Reform and Consumer Protection Act. The American law expands stress testing to smaller institutions that escape the CCAR. The act also features extensive compliance and reporting procedures for swaps and other over-the-counter derivative contracts.
- European Market Infrastructure Regulation. Although less broad in scope than Dodd-Frank, EMIR has similar reporting requirements for European institutions regarding OTC derivatives.
- AnaCredit, Becris and FR Y-14. The European Central Bank project, known formally as the Analytical Credit Dataset, and its Federal Reserve equivalent for American banks, respectively, introduce a step change in the amount and granularity of data that needs to be reported. Information on loans and counterparties must be reported contract by contract under AnaCredit, for example. Adding to the complication and the data demands, the European framework permits national variations, including some with particularly rigorous requirements, such as the Belgian Extended Credit Risk Information System (Becris).
- MAS 610. The core set of returns that banks file to the Monetary Authority of Singapore are being revised to require information at a far more granular level beginning next year. The number of data elements that firms have to report will rise from about 4,000 to about 300,000.
- Economic and Financial Statistics Review (EFS). The Australian Prudential Authority’s EFS Review constitutes a wide-ranging update to the regulator’s statistical data collection demands. The sweeping changes include requests for more granular data and new forms in what would be a three-phase implementation spanning two years, requiring parallel and trial periods running through 2019 and beyond.
All of those authorities, all over the world, requiring that much more information present a daunting challenge, but they aren’t the only ones demanding that finance, risk and regulatory reporting staffs raise their games. Boards, senior executives and the real bosses – shareholders – have more stringent requirements of their own for profitability, capital efficiency, safety and competitiveness. Firms need to develop more effective data management and analysis in this cause, too.
The critical role of data management was emphasized and codified in Document 239 of the Basel Committee on Banking Supervision (BCBS), “Principles for Effective Risk Data Aggregation and Risk Reporting.” PERDARR, as it has come to be called in the industry, assigns data management a central position in the global supervisory architecture, and the influence of the 2013 paper can be seen in mandates far and wide. BCBS 239 explicitly linked a bank’s ability to gauge and manage risk with its ability to function as an integrated, cooperative unit rather than a collection of semiautonomous fiefdoms. The process of managing and reporting data, the document makes clear, enforces the link and binds holistic risk assessment to holistic operating practices. The Basel committee’s chief aim was to make sure that institutions got the big picture of their risk profile so as to reveal unhealthy concentrations of exposure that might be obscured by focusing on risk segment by segment. Just in case that idea might escape some executive’s notice, the document mentions the word “aggregate,” in one form or another, 86 times in the 89 ideas, observations, rules and principles it sets forth.
The importance of aggregating risks, and having data management and reporting capabilities that allow firms to do it, is spelled out in the first of these: ‘One of the most significant lessons learned from the global financial crisis that began in 2007 was that banks’ information technology (IT) and data architectures were inadequate to support the broad management of financial risks. Many banks lacked the ability to aggregate risk exposures and identify concentrations quickly and accurately at the bank group level, across business lines and between legal entities. Some banks were unable to manage their risks properly because of weak risk data aggregation capabilities and risk reporting practices. This had severe consequences to the banks themselves and to the stability of the financial system as a whole.’
If risk data management was an idea whose time had come when BCBS 239 was published five years ago, then RegTech should have been the means to implement the idea. RegTech was being touted even then, or soon after, as a set of solutions that would allow banks to increase the quantity and quality of the data they generate, in part because RegTech itself was quantitatively and qualitatively ahead of the hardware and software with which the industry had been making do. There was just one ironic problem: Many of the RegTech solutions on the market at the time were highly specialized and localized products and services from small providers. That encouraged financial institutions to approach data management deficiencies gap by gap, project by project, perpetuating the compartmentalized, siloed thinking that was the scourge of regulators and banks alike after the global crisis. The one-problem-at-a-time approach also displayed to full effect another deficiency of silos: a tendency for work to be duplicated, with several departments each producing the same information, often in different ways and with different results. That is expensive and time consuming, of course, and the inconsistencies that are likely to crop up make the data untrustworthy for regulators and for executives within the firm that are counting on it.
Probably the most critical feature of a well thought-out solution is a dedicated, focused and central FRR data warehouse that can chisel away at the barriers between functions, even at institutions that have been slow to abandon a siloed organizational structure reinforced with legacy systems.
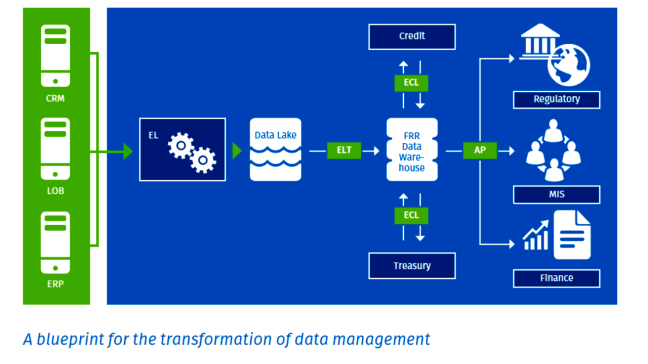
With :
- E : Extract
- L : Load
- T : Transform Structures
- C : Calculations
- A : Aggregation
- P : Presentation
Click here to access Wolters Kluwer’s White Paper
